
I shipped a Node.js auth API with 87% test coverage and an obvious bug in production within a week. Coverage was junit-style: every branch had a unit test, every controller had a happy-path call. What it didn’t have was an integration test that ran the actual login flow against a real Postgres. The bug was a Prisma transaction that only fired when two users registered with the same email simultaneously — a unique constraint race. Coverage said green; production said 500. That is the moment I rebuilt how I test a Node.js API with Jest — and switched most projects from Jest to Vitest while I was at it.
This is the test suite I now lift onto every Node.js project. Same shape every time, runs in 8 seconds locally for 200 tests, in 22 seconds in CI with a fresh container.
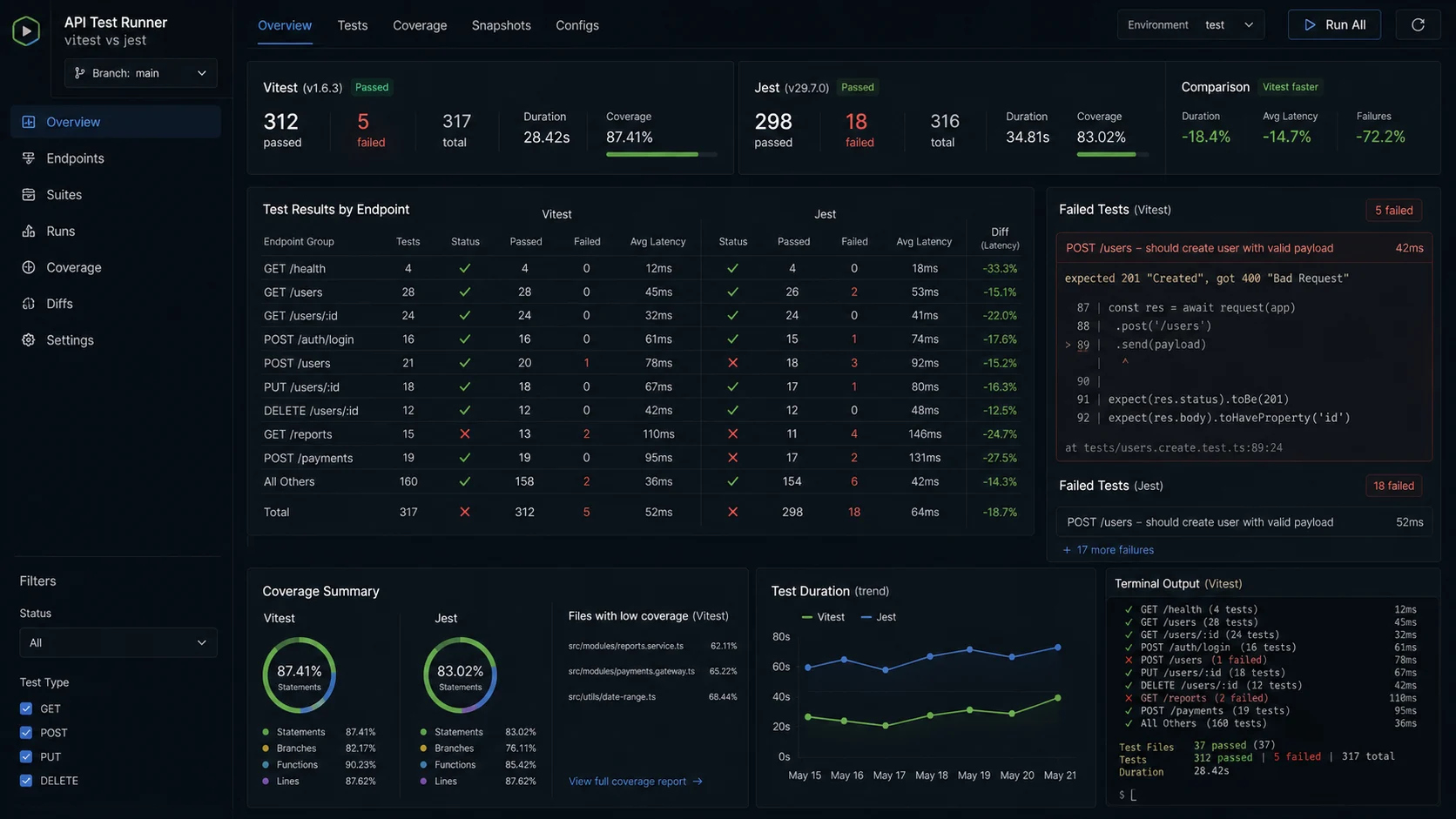
Jest 30 vs Vitest 3 in 2026 (the comparison nobody runs honestly)
| Dimension | Jest 30 | Vitest 3 |
|---|---|---|
| Cold start (TS, 200 tests, Node 24) | ~3.4 s | ~0.9 s |
| Watch-mode re-run on save | ~1.0 s | ~110 ms |
| Native ESM | Yes (Jest 30 reworked it) | Yes, day-one |
| TypeScript | Needs ts-jest or @swc/jest |
Built in via Vite |
| Mocking API | Mature; jest.mock |
Compatible; vi.mock |
| Snapshot testing | Yes | Yes (Jest-compatible) |
| Inline snapshots | Yes | Yes |
| Browser mode | jsdom / happy-dom only | Native browser via Playwright |
| Workspace / monorepo support | Projects field | First-class via vitest.workspace.ts |
| Ecosystem age | 10+ years | ~4 years, broad coverage |
| Config size for a TS Node API | 10–25 lines + transform | 5–10 lines |
For a new Node.js project in 2026, I reach for Vitest. The dev loop alone is worth the switch — re-running a single test on save in 110ms changes how you write tests. Jest 30 is still excellent and the right call if you already have a thousand-test Jest suite that you don’t want to migrate, or if you depend on a Jest-specific runner plugin (Storybook’s, for example, until it ports cleanly).
Step 1: install Vitest 3 with the working defaults
npm i -D vitest@^3 @vitest/coverage-v8 supertest@^7 @types/supertest// vitest.config.ts
import { defineConfig } from "vitest/config";
export default defineConfig({
test: {
globals: false,
environment: "node",
include: ["src/**/*.{test,spec}.ts"],
coverage: {
provider: "v8",
reporter: ["text", "html", "lcov"],
exclude: ["**/*.test.ts", "src/test/**", "dist/**", "src/types/**"],
thresholds: {
lines: 80,
functions: 80,
branches: 75,
statements: 80,
},
},
setupFiles: ["src/test/setup.ts"],
pool: "forks",
poolOptions: {
forks: { singleFork: false },
},
isolate: true,
testTimeout: 10_000,
},
});Three settings here matter more than the rest. pool: "forks" isolates each test file in its own process — slower than threads for pure-function tests, but it is the only safe choice for any test that touches a database, a Redis connection, or a module-level singleton. The default "threads" pool shares the V8 isolate across files, which causes subtle bugs with Prisma’s connection pool and any cached import.meta-keyed state. Pay the 50ms-per-file overhead.
isolate: true is the second non-obvious one. It prevents test pollution across files — every file gets a fresh module graph. globals: false is the third — I don’t want describe/it/expect as ambient globals; explicit imports survive a typo and play nicer with editor autocomplete. Vitest reads your existing tsconfig.json directly — no ts-jest, no @swc/jest. The TypeScript Node setup that pairs with this is in the TypeScript Node.js setup guide.
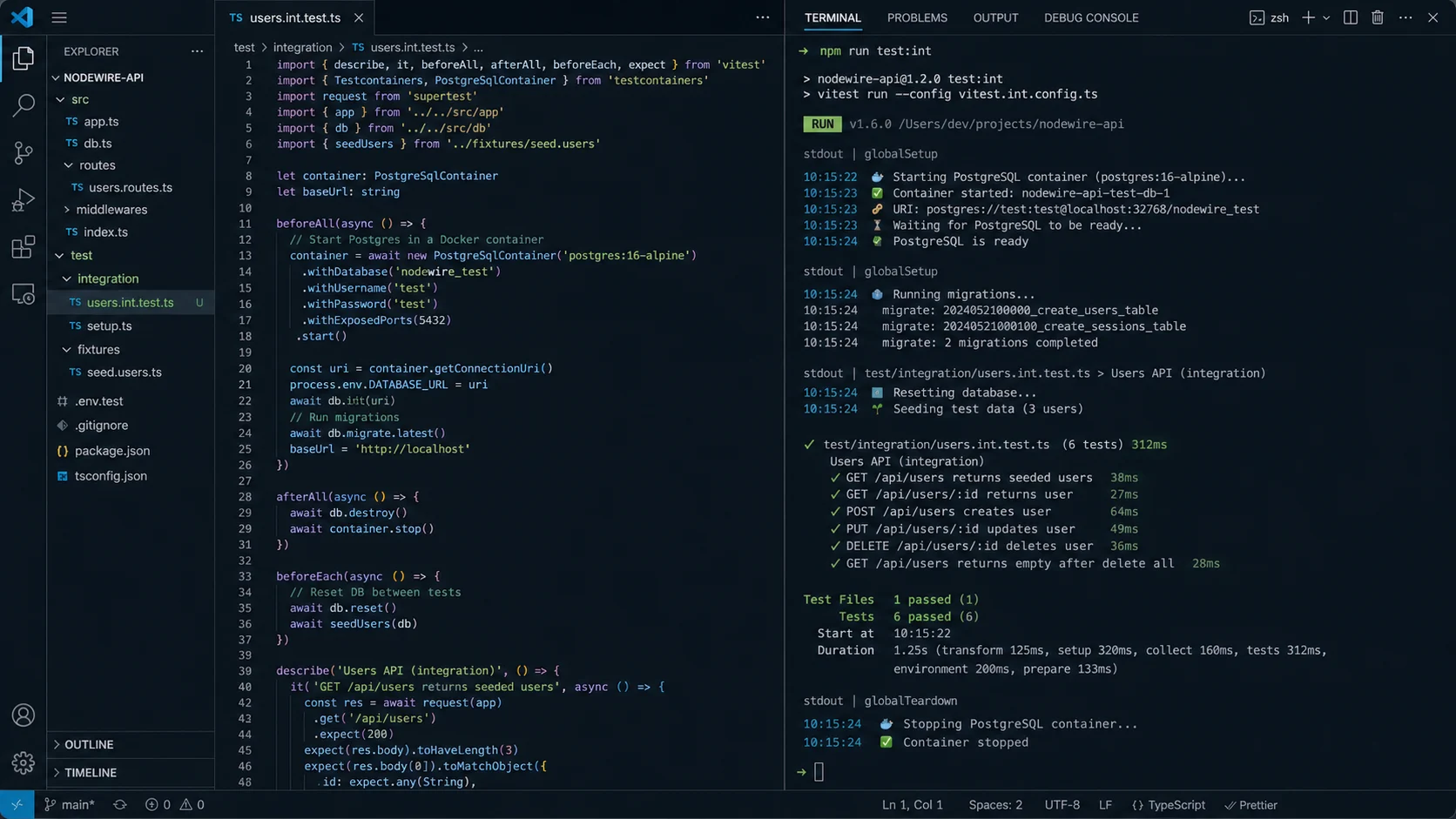
Step 2: integration tests against a real database (Testcontainers)
The single highest-value change in my testing setup: integration tests that spin up a real Postgres in a container, run real migrations, and exercise real queries. Mocked databases find type errors. Real ones find logic errors.
npm i -D @testcontainers/postgresql// src/test/setup.ts
import { PostgreSqlContainer, StartedPostgreSqlContainer } from "@testcontainers/postgresql";
import { execSync } from "node:child_process";
import { beforeAll, afterAll } from "vitest";
let container: StartedPostgreSqlContainer;
beforeAll(async () => {
container = await new PostgreSqlContainer("postgres:17-alpine")
.withDatabase("test")
.withUsername("test")
.withPassword("test")
.withReuse() // keep container between runs locally
.start();
process.env.DATABASE_URL = container.getConnectionUri();
// Apply schema once to a "template" database; clone it per test file later.
execSync("npx prisma migrate deploy", { stdio: "inherit", env: process.env });
}, 60_000);
afterAll(async () => {
if (!process.env.CI) return; // .withReuse() handles local cleanup
await container.stop();
});Container starts once per test run (or stays warm locally with .withReuse()), migrations apply, every test gets a real Postgres on a real port. First run is slow (image pull, ~15 s). Every subsequent run reuses the cached image and starts in ~3 seconds. The Prisma migration setup itself is in the Node.js Postgres + Prisma setup guide.
One non-obvious cost: the first beforeAll in CI takes 12–15 seconds for the cold pull of postgres:17-alpine. Cache the image in CI by pinning the digest and pulling explicitly in a setup step before tests run. Otherwise every PR pays the cold-pull cost.
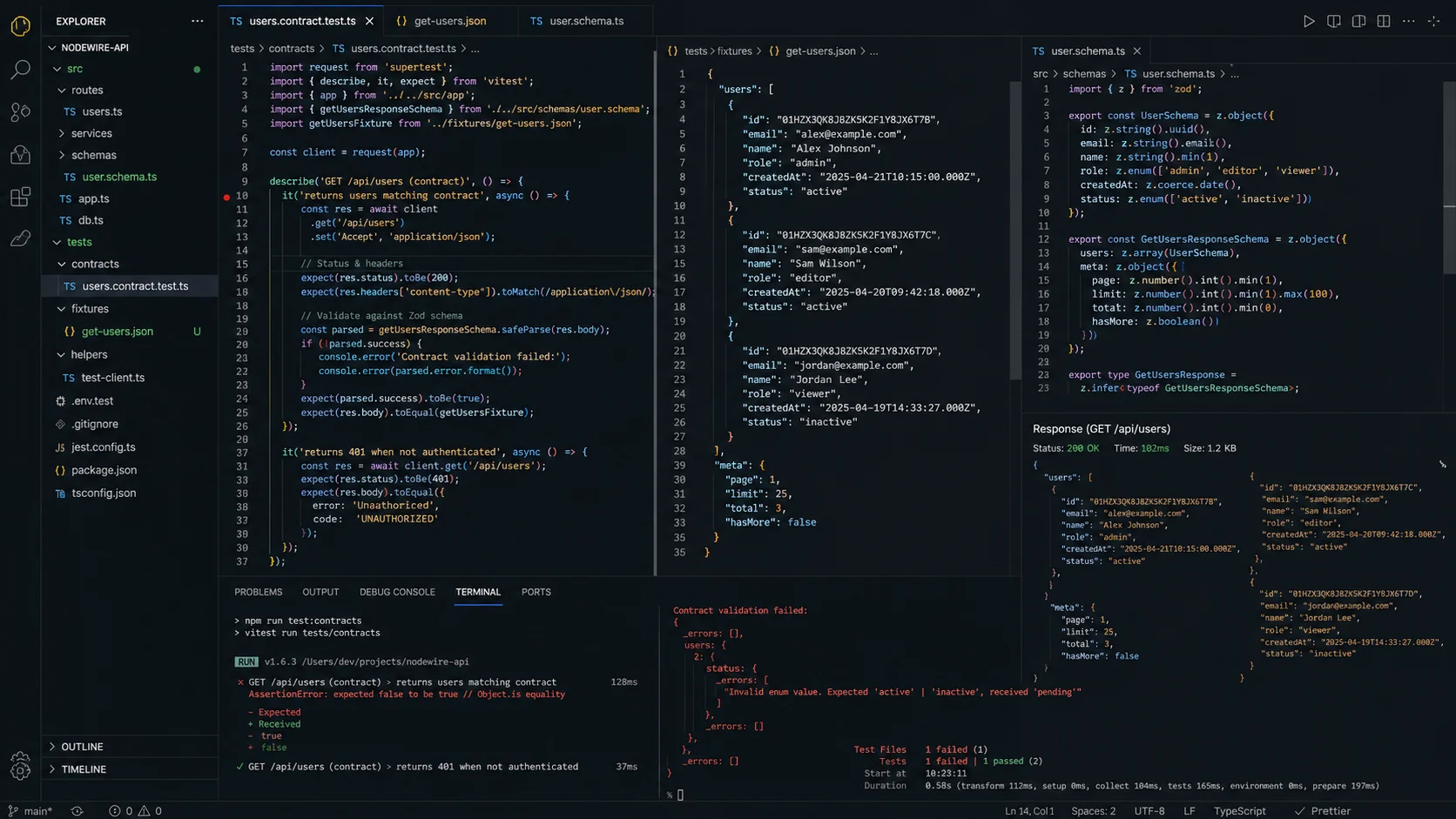
Step 3: HTTP testing with supertest 7.x
For the actual API requests, supertest is still the standard. It wraps your Express or Fastify app and lets you make HTTP-style assertions without binding to a real port — supertest manages the connection lifecycle on an ephemeral port per test.
// src/auth/login.test.ts
import { describe, it, expect, beforeEach } from "vitest";
import request from "supertest";
import { app } from "../app.js";
import { db } from "../db.js";
import { hashPassword } from "../auth/password.js";
describe("POST /auth/login", () => {
beforeEach(async () => {
await db.user.deleteMany();
await db.user.create({
data: {
email: "ethan@example.com",
passwordHash: await hashPassword("correct horse battery staple"),
},
});
});
it("returns a JWT for valid credentials", async () => {
const res = await request(app)
.post("/auth/login")
.send({ email: "ethan@example.com", password: "correct horse battery staple" })
.expect(200);
expect(res.body).toHaveProperty("accessToken");
expect(res.body.accessToken.split(".")).toHaveLength(3);
});
it("returns 401 for wrong password", async () => {
await request(app)
.post("/auth/login")
.send({ email: "ethan@example.com", password: "wrong" })
.expect(401);
});
it("does not leak whether the email exists", async () => {
const wrongEmail = await request(app)
.post("/auth/login")
.send({ email: "nobody@example.com", password: "x" });
const wrongPw = await request(app)
.post("/auth/login")
.send({ email: "ethan@example.com", password: "x" });
expect(wrongEmail.status).toBe(401);
expect(wrongPw.status).toBe(401);
expect(wrongEmail.body.error).toBe(wrongPw.body.error);
});
});Three tests, but the third one — the «does not leak whether the email exists» test — is the kind of thing only integration tests catch. Mocked-database tests pass it trivially because both branches return 401 with whatever shape the mock decides. Real-database tests catch the case where one branch hashes a password (the email-exists branch) and the other returns immediately (the email-doesn’t-exist branch), giving the username away through response timing or message shape. The JWT authentication guide covers the actual login implementation these tests are exercising.
One critical detail in the imports: import { app } from "../app.js". The app module exports the Express instance without calling .listen(). server.ts imports app and calls listen() for production. Test files import app directly. Otherwise every test file tries to bind port 3000 and you get EADDRINUSE on the second file in the suite (the EADDRINUSE fix article explains the underlying cause).
Step 4: the trick that makes mocking sane
Vitest’s vi.mock hoists like Jest’s. It runs before imports, even if you write it after them. The pattern that reliably works for ESM Node:
import { describe, it, expect, vi, beforeEach } from "vitest";
vi.mock("../email/send-email.js", () => ({
sendEmail: vi.fn().mockResolvedValue({ id: "msg_test_1" }),
}));
import { registerUser } from "./register.js";
import { sendEmail } from "../email/send-email.js";
describe("registerUser", () => {
beforeEach(() => {
vi.clearAllMocks();
});
it("sends a welcome email", async () => {
await registerUser({ email: "new@example.com", password: "letmein123!" });
expect(sendEmail).toHaveBeenCalledWith(
expect.objectContaining({
to: "new@example.com",
template: "welcome",
}),
);
});
it("does not send a second email on duplicate registration", async () => {
await registerUser({ email: "new@example.com", password: "letmein123!" });
await expect(
registerUser({ email: "new@example.com", password: "letmein123!" }),
).rejects.toThrow(/already exists/);
expect(sendEmail).toHaveBeenCalledTimes(1);
});
});Mock outbound side effects — email, payment provider, third-party HTTP, Slack webhooks. Don’t mock your own database. The temptation is real (“but it’ll be faster”) but the result is the bug I opened with: tests pass, production breaks because the mock didn’t enforce the unique constraint. Real integration tests against a Testcontainer DB are not slow enough to justify the lie.
For HTTP-level mocking (a third-party API your code calls via fetch), MSW intercepts at the network layer and works for both fetch and axios without per-test mocking. MSW shines when you have multiple call sites for the same upstream — write the handler once, every test that hits the URL gets the mocked response.
Step 5: the test that catches what coverage misses
One contract test per public endpoint. It asserts that the response shape matches what the client expects — typically validated against a Zod schema you also use for runtime validation:
// src/auth/login.contract.test.ts
import { describe, it, expect } from "vitest";
import { z } from "zod";
import request from "supertest";
import { app } from "../app.js";
const LoginResponseSchema = z.object({
accessToken: z.string().min(20),
refreshToken: z.string().min(20),
user: z.object({
id: z.string().uuid(),
email: z.string().email(),
createdAt: z.string().datetime(),
}),
});
describe("POST /auth/login contract", () => {
it("response matches the documented shape", async () => {
const res = await request(app)
.post("/auth/login")
.send({ email: "ethan@example.com", password: "correct horse battery staple" });
const parsed = LoginResponseSchema.safeParse(res.body);
if (!parsed.success) {
console.error(parsed.error.issues);
}
expect(parsed.success).toBe(true);
});
});The schema is the API contract. If a refactor changes the response shape — drops a field, renames it, returns a number where a string was promised — this test fails before any client does. Unit tests that mock the response don’t catch this because the mock is the shape; it can never diverge from the contract.
Step 6: fixtures, transactions, and database state
Don’t share state between tests. Three patterns work, in order of speed:
| Pattern | Speed | Isolation | Complexity | When |
|---|---|---|---|---|
| Truncate before each test | ~30ms/test | Full | Low | Default — works everywhere |
| Postgres template DB clone | ~10ms/test | Full | Medium | 200+ tests, fast feedback |
| Transaction + rollback per test | ~5ms/test | Full | High | Pure read tests; awkward with Prisma’s connection pooling |
| Shared seed, no cleanup | 0ms/test | None | Trivial | Never. It will bite you. |
// src/test/fixtures.ts — truncate-on-each, the default
import { beforeEach } from "vitest";
import { db } from "../db.js";
beforeEach(async () => {
await db.$executeRawUnsafe(`
TRUNCATE TABLE "User", "Session", "Order", "OrderItem"
RESTART IDENTITY CASCADE
`);
});For Prisma + Postgres, the savepoint/transaction pattern works but adds Prisma-specific complexity (you need a custom PrismaClient that runs every test inside a single interactive transaction and rolls back at the end). For most projects, truncate-on-each is fast enough and bulletproof. Tests that exercise async error paths need your error middleware wired correctly — the Express async error handling guide covers the pattern.
The Postgres template-database trick is worth knowing about even if you don’t use it: create one «template» database with the schema applied, then CREATE DATABASE test_X TEMPLATE template_db per test file. Cloning is faster than running migrations from scratch, and gives every file its own isolated DB.
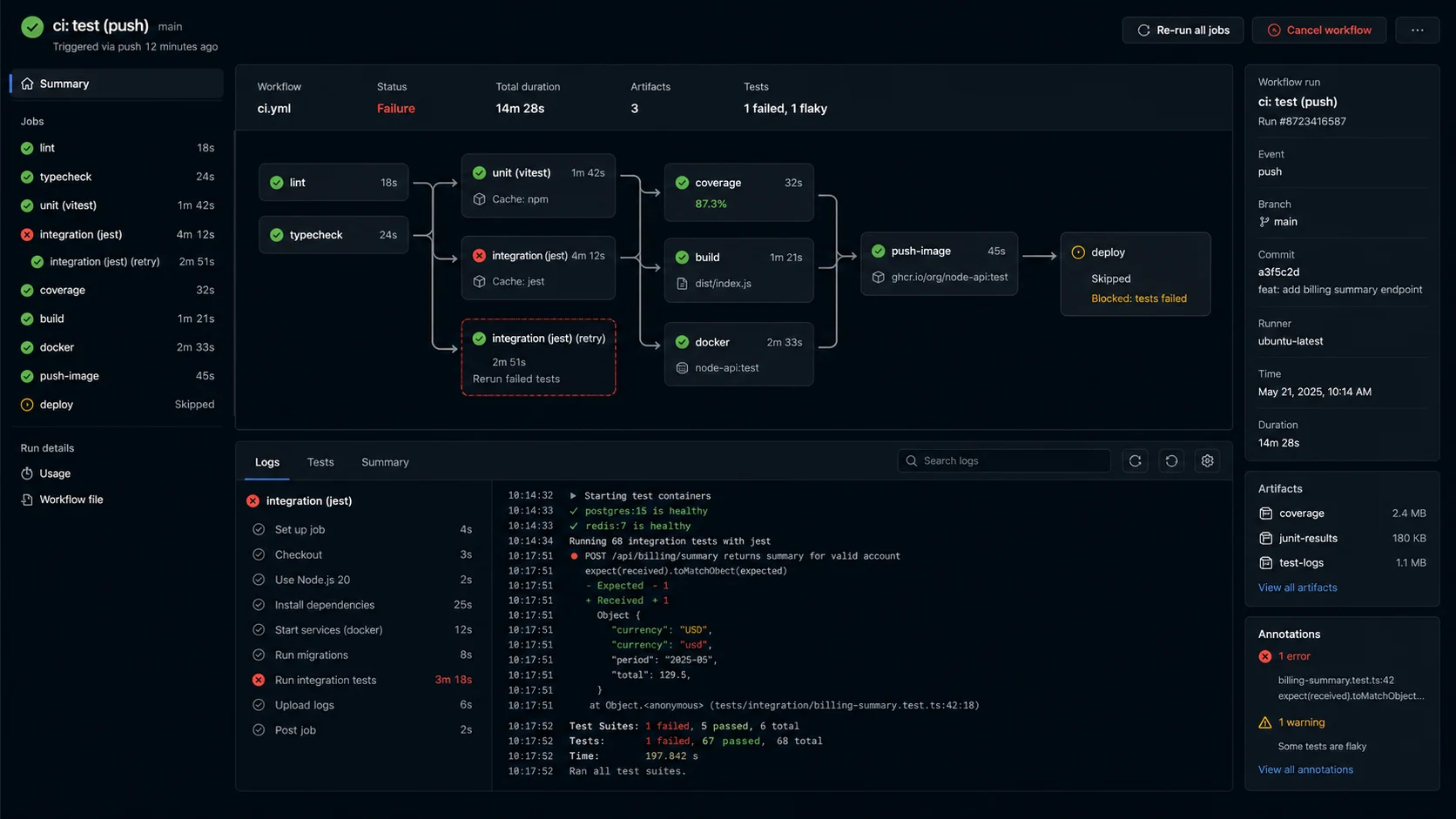
Step 7: CI pipeline that catches the right things
# .github/workflows/test.yml
name: tests
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: "24"
cache: "npm"
- run: npm ci
- run: npm run typecheck
- run: npm run lint
- run: docker pull postgres:17-alpine
- run: npx vitest run --coverage
- uses: codecov/codecov-action@v4
with: { files: ./coverage/lcov.info }Type-check and lint before tests. Both are faster, both catch a class of bug Vitest will never find. A failing typecheck means the test is going to fail anyway — fail fast and save CI minutes. Pull the Postgres image explicitly so the beforeAll hook in setup.ts doesn’t pay the cold-pull cost. Run vitest run (not vitest) so you don’t accidentally enter watch mode in CI.
For services with background workers, run a separate worker-test job that exercises BullMQ jobs end-to-end against a Redis container — same Testcontainers pattern, different image.
Step 8: migration path from Jest 30 to Vitest 3
If you have an existing Jest suite, migration is mostly mechanical. The four changes that account for 90% of the work:
- Replace globals with imports. Jest exposes
describe,it,expect,beforeAll,jestas globals. Vitest exposes them as named exports from"vitest". A codemod handles this —npx jest-to-vitest srcworks for most cases. jest.mock→vi.mock. Same hoisting, same factory signature, same return shape. Find/replace.- Drop
ts-jest/babel-jest. Vitest readstsconfig.jsondirectly. Delete the transform config, delete the dev deps. jest.config.js→vitest.config.ts. Most options translate 1:1 (setupFiles,testTimeout,coverageThreshold). Workspaces arevitest.workspace.tswith a list of project paths.
The traps: any test that depended on Jest’s specific timer mocking semantics may behave differently under Vitest’s vi.useFakeTimers(); Jest’s snapshot serializer plugins may not have a Vitest equivalent and you may need to write the serialiser yourself; and any custom Jest reporter has to be ported. Budget a day for a 500-test suite, more if you have heavy snapshot reliance.
When NOT to write a given test
- Pure framework wiring. A test that asserts
app.use(express.json())is called doesn’t catch any bug. It only breaks when you refactor — it’s a refactor-blocker, not a safety net. Skip it. - External SDKs you don’t own. Don’t write a unit test that mocks the OpenAI SDK and asserts you called
chat.completions.create. Mock the response, test your handling of it. The integration test against the real SDK lives in a manual smoke run or a nightly job, not the per-PR suite. - Implementation details. Test behaviour, not internals.
expect(controller.privateMethod).toHaveBeenCalled()is a refactor-blocker. If you delete the private method and split it into two, the test fails despite the user-visible behaviour being identical. - Trivial getters and pass-through code. A test that asserts
user.emailreturnsuser.emailis noise. Coverage tools may yell about it; ignore them. - Third-party library internals. Don’t write tests that exercise Express’s router. The Express maintainers do that. Test your code, not theirs.
Decision matrix: what kind of test for what kind of code
| Code type | Test type | Tool | Database |
|---|---|---|---|
| Pure utility function (date math, string parse) | Unit | Vitest | None |
| Validation / schema (Zod parsers) | Unit | Vitest | None |
| Route handler with business logic | Integration | Vitest + supertest | Real Postgres (Testcontainer) |
| Auth middleware | Integration | Vitest + supertest | Real Postgres |
| Database query layer (Prisma) | Integration | Vitest | Real Postgres |
| BullMQ background job | Integration | Vitest | Real Redis (Testcontainer) |
| Code that calls a third-party API | Unit (mocked) | Vitest + MSW | None |
| Public API response shape | Contract | Vitest + Zod schema | Real Postgres |
| Static React component | Component | Vitest browser mode | None |
Production checklist
- Vitest 3 on a new project, Jest 30 if you’re already in a large Jest suite.
- Real database via Testcontainers for any test that touches the DB. Mocked DBs catch type errors, not logic errors.
- App exported without
.listen()so supertest can bind ephemeral ports per test. - Outbound side effects mocked (email, payment, third-party HTTP); your own DB is not an «outbound side effect».
- Truncate-on-each for fixture management. Template-DB cloning if your suite is over 200 tests.
- Contract tests against a Zod schema for every public endpoint. Catches response-shape regressions before clients do.
pool: "forks"for any DB-touching test.isolate: true.globals: false.- Coverage gate at 80% lines / 75% branches. Higher is vanity; lower means dead code.
- CI pre-pulls Docker images so
beforeAlldoesn’t pay the cold-pull cost. - Type-check and lint before tests in CI. Faster, catches a different class of bug.
- Health-check endpoints don’t run through the limiter in tests either — keep the rate limiter wired but configured for high limits in
NODE_ENV=testso you don’t get 429s on parallel test runs (the rate limiting article covers this).
Troubleshooting FAQ
Should I use Jest or Vitest for Node.js in 2026?
Vitest 3 for new projects — faster cold start, native ESM, native TypeScript via Vite, Jest-compatible API. Stay on Jest 30 if you already have a large suite that you don’t want to migrate; the migration is mostly mechanical but has rough edges around custom transformers, snapshot serialisers, and any plugin that depends on Jest’s runner internals.
How do I test a Node.js Express API?
Use supertest to make HTTP requests against your app instance without binding to a port. Pair it with a real database in a Testcontainer for integration tests. Mock outbound side effects (email, payments, third-party HTTP) but don’t mock your own data layer. Export app without calling .listen() so supertest can manage the connection lifecycle.
What is the difference between unit and integration tests?
Unit tests exercise a single function in isolation, with all dependencies mocked. Integration tests exercise multiple components together (controller + service + database) using real implementations. Both have value. Coverage from one doesn’t substitute for the other — most «coverage looked great, prod broke» stories are the unit/integration trade-off going wrong.
Do I need to test against a real database?
Yes for any API that does meaningful data work. Mocks pass when your queries are wrong. Testcontainers (or a docker-compose Postgres) gives you real-database confidence with reproducible setup. The first run is slow because of the image pull; subsequent runs are sub-second to start.
How do I mock fetch or axios in Vitest?
vi.mock("axios") works the same as Jest. For fetch, install MSW — it intercepts at the network layer and works for both fetch and axios without per-test mocking. MSW also gives you one definition that works in both Node tests and browser tests.
What coverage threshold should I aim for?
80% lines / 75% branches is a healthy minimum. Past 90%, the marginal coverage costs more than it returns. Coverage is a smell, not a goal — chase it for honest reasons (untested error paths, untested edge cases) and skip it for dishonest ones (untested glue code that has no logic, untested type-narrowing branches).
How do I test authenticated routes?
Generate a real JWT in a beforeAll hook using your own signing function and attach it as a Bearer header: request(app).get("/api/profile").set("Authorization", `Bearer ${token}`). Test against a real user row in your Testcontainer DB. The JWT authentication article shows the signing helper.
How do I prevent test pollution between test files?
Set isolate: true in your Vitest config (the default in v3) and use beforeEach to clear the database after every test. Avoid global mutable state shared across test files. pool: "forks" isolates each file in its own process, which is the only safe option when you have module-level state like a Prisma client or a Redis connection.
Why does my test sometimes pass and sometimes fail?
Either you’re sharing state between tests (truncate before each), depending on real timestamps without freezing them (vi.useFakeTimers()), or hitting a real third-party API with rate limits. Flakiness is a category, not a test-by-test problem — once you have one flaky test you’ll get more unless you fix the root cause.
Should I use describe.concurrent or it.concurrent?
Rarely. Vitest already runs files in parallel. Within a file, concurrent tests share state — including database connections — and you trade test reliability for tens of milliseconds. Stick to file-level parallelism and keep within-file tests sequential.
Is 100% test coverage a good goal?
No. It becomes a vanity metric that incentivises testing trivial code. A 100%-covered codebase with bad tests is worse than a 70%-covered codebase with sharp ones. Focus coverage on your most critical paths — payment flows, auth logic, data transformations, anything customer-visible — and accept that some glue code will go uncovered.
The test pyramid that actually survives audits
The «test pyramid» is one of those terms that’s easy to wave at and hard to act on. Here’s the honest distribution I run on every Node.js project, with the numbers that make a 200-test suite tractable:
| Layer | % of suite | Time per test | What it catches | What it misses |
|---|---|---|---|---|
| Pure unit (no I/O) | 40–50% | ~2ms | Logic bugs in helpers, parsers, validators | Anything that crosses a module boundary |
| Integration (real DB) | 30–40% | ~30–60ms | SQL bugs, transaction races, real Prisma queries | UI / network failure modes |
| Contract (Zod schemas) | 5–10% | ~30ms | Response shape regressions | Behaviour bugs |
| End-to-end (real HTTP, real services) | 5% | seconds | Auth flows, multi-step user journeys | Slow; flaky if upstream is |
| Manual smoke (third-party SDKs) | — | — | Real Stripe / OpenAI / Twilio behaviour | Not in CI; runs nightly |
The single most common mistake I see is teams writing 80% pure unit tests, hitting 90% coverage, and shipping the bug from the intro of this article. The fix isn’t more tests — it’s redistributing toward integration. Integration tests cost 15× more wall time per test and catch 5× more real production bugs. The trade is worth it.
What ships next
The test suite catches the bugs you can think of. The bugs you can’t think of are caught by structured logging, error tracking (Sentry), and request tracing — your error handling middleware sees every failure that escapes a handler. Postgres + Prisma covers the data layer the integration tests are exercising. JWT authentication covers the login flow these tests open with. Rate limiting on /auth/login is the production-side counterpart of the «5 wrong passwords lock the account» test that should already be in your suite. Together they make «coverage looked great, prod broke» a story you tell once.