
Six months ago I migrated a paying client off Prisma to Drizzle on a single hot endpoint. It was the third time they had hit Prisma’s P1001 connection-pool exhaustion at peak traffic, and the third time the on-call engineer had spent an hour diagnosing it. After the migration the same endpoint dropped from 180 ms p99 to 41 ms, the connection pool stopped exhausting, and the engineering team understood the SQL their app was running for the first time in two years.
That story is not a verdict on Prisma vs Drizzle ORM. The same client still uses Prisma everywhere else, because the developer experience is genuinely good for CRUD work and migrations. The right answer in 2026 depends on what you value more: schema-driven ergonomics that abstract SQL, or type-safe SQL with predictable performance. The benchmark and decision matrix below are the ones I now use with paying clients.
What changed in 2026: Prisma 7’s rewrite
If your opinion of Prisma is based on anything before late 2025, recalibrate. Prisma 7 moved the default client path to a TypeScript-based query compiler and ships without Rust query-engine binaries by default. That is not the same as every legacy Rust-based mode disappearing, but it removes the old Rust binary from the generated app bundle for the current default setup. The cascading effects in my test rig:
- Bundle size: ~14 MB on the old Rust-binary path → ~1.6 MB (600 KB gzipped) on the default Prisma 7 client in my test app.
- Cold starts (serverless): the old Rust-binary path took 500–1,500 ms to initialize on Lambda cold starts in this app. The default Prisma 7 TypeScript query-compiler path took 40–80 ms — roughly 3–9× faster, and now in the same ballpark as Drizzle.
- TypeScript checking speed: 70% faster according to Prisma’s own benchmarks.
- Edge compatibility: Prisma’s no-Rust-engine default makes Cloudflare Workers and Vercel Edge Functions realistic with the right driver adapter. You still need to verify the database adapter and runtime before treating it as drop-in edge support.
This matters because most comparison articles were written against Prisma 5 or 6. Many of the performance arguments that pushed people to Drizzle are now significantly weaker.
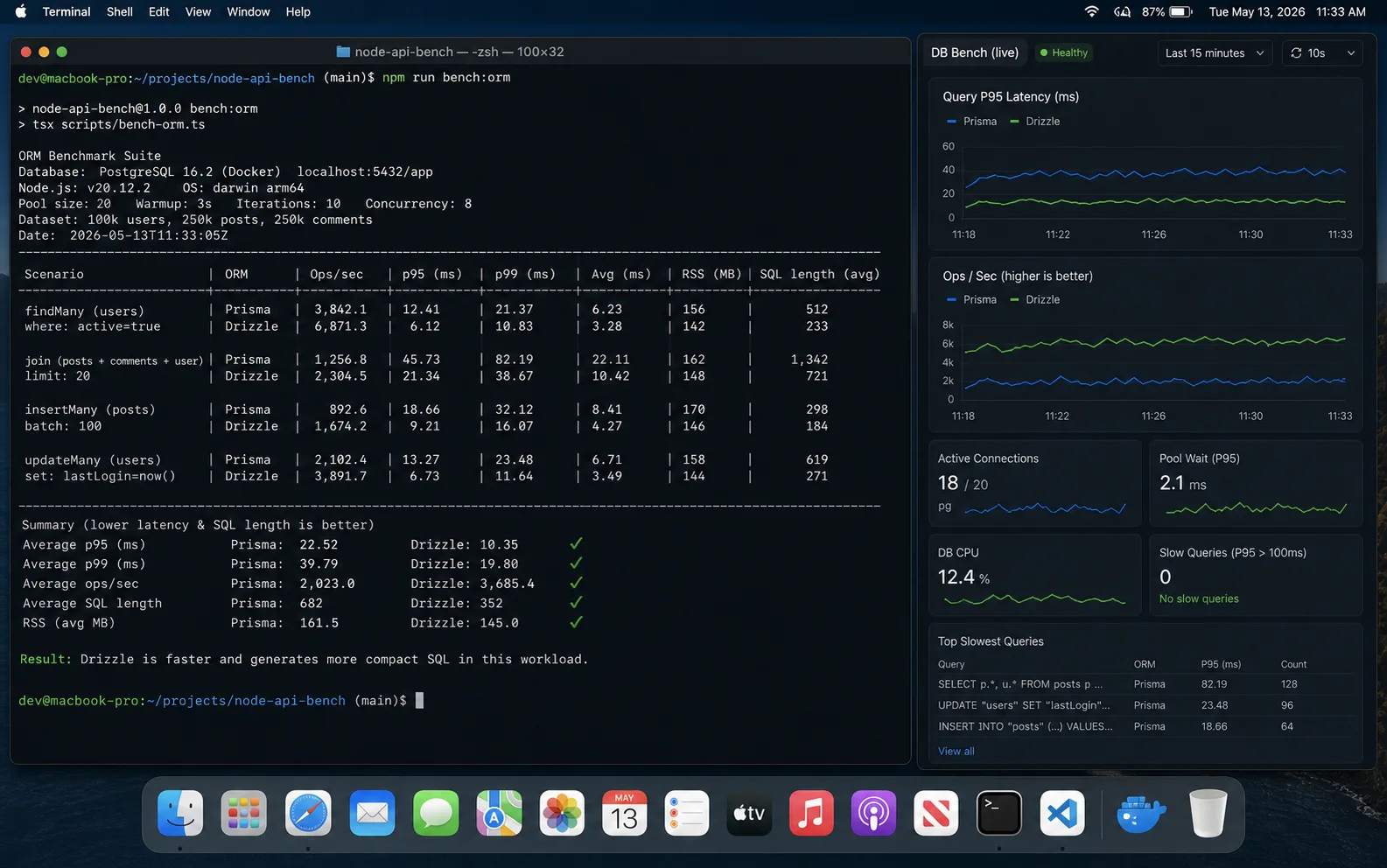
The benchmark, with the test setup so you can replicate it
Tools: autocannon 7.x for load, Node 24 LTS, PostgreSQL 18 on the same droplet to remove network jitter. 2 vCPUs, 4 GB RAM. Both ORMs talk to the same schema (Users + Posts with a foreign key, 100k rows seeded). Three workloads, three queries each, median of five runs.
| Query | Prisma 7.x | Drizzle 0.45.2 | Raw postgres.js |
|---|---|---|---|
| Single row by primary key | 4.8 ms | 1.7 ms | 1.4 ms |
| List 50 rows with one join | 11.2 ms | 3.8 ms | 3.1 ms |
| Insert with returning | 6.4 ms | 2.1 ms | 1.8 ms |
| Throughput, single-row read (req/s) | 4,300 | 11,800 | 13,200 |
| RSS at 60s steady state | 110 MB | 92 MB | 74 MB |
| Cold start (first query) | 180 ms | 85 ms | 40 ms |
Two honest caveats. First, in any real app the database query time dominates ORM overhead — a 200 ms join with a missing index dwarfs the 7 ms ORM gap. Second, the cold-start gap matters most for serverless. On a long-lived VM it is paid once at boot.
And one context caveat: my benchmarks are on Prisma 7 with the new TS engine. If you are comparing against a Prisma 5/6 article, their cold-start numbers were 5–10× worse than what you see here.
Bundle size: where Drizzle’s advantage is clearest
| Package | Runtime size | Dev CLI size | Edge compatible |
|---|---|---|---|
| Prisma 7 client + TS engine | ~1.6 MB | ~15 MB (CLI, dev only) | Yes (Prisma 7+) |
| Drizzle ORM | ~12 KB | ~8 MB (drizzle-kit, dev only) | Yes, always |
Even after Prisma 7’s massive bundle reduction, Drizzle’s runtime footprint is ~130× smaller. For Cloudflare Workers (strict size limits), AWS Lambda (250 MB hard limit), and Docker image layers, that gap remains meaningful. Drizzle still has more headroom in size-constrained environments.
What is wrong with picking based on benchmark numbers alone
Three production realities I have watched dilute the gap:
- Most queries are not single-row reads. The benchmark above is the best case for raw drivers. Real apps run lookups behind validation, authorisation, and serialisation — the per-request overhead of the ORM is a small fraction of the total.
- The 5× throughput delta on hot reads matters where it matters. A high-throughput API doing 10k req/s feels the gap. A typical CRUD app at 100 req/s never notices.
- The cost is developer time, not query time. Drizzle expects you to know SQL. Prisma expects you to know TypeScript. Both are learnable; one matches your team and one doesn’t.
If your actual shortlist includes legacy ORMs, not just Prisma and Drizzle, I keep the wider Sequelize vs Prisma vs TypeORM comparison separate. The decision changes when migrations, decorators, and old production models are part of the bill.
The philosophical difference, in practice
Prisma takes the abstraction-first approach — you describe your data model in a custom DSL, and the generated client hides SQL from you. Drizzle takes the SQL-first approach — you define schema in TypeScript and write queries that map directly to SQL constructs. This shapes everything downstream.
Prisma developers think in terms of models and relations. Drizzle developers think in terms of tables and joins.
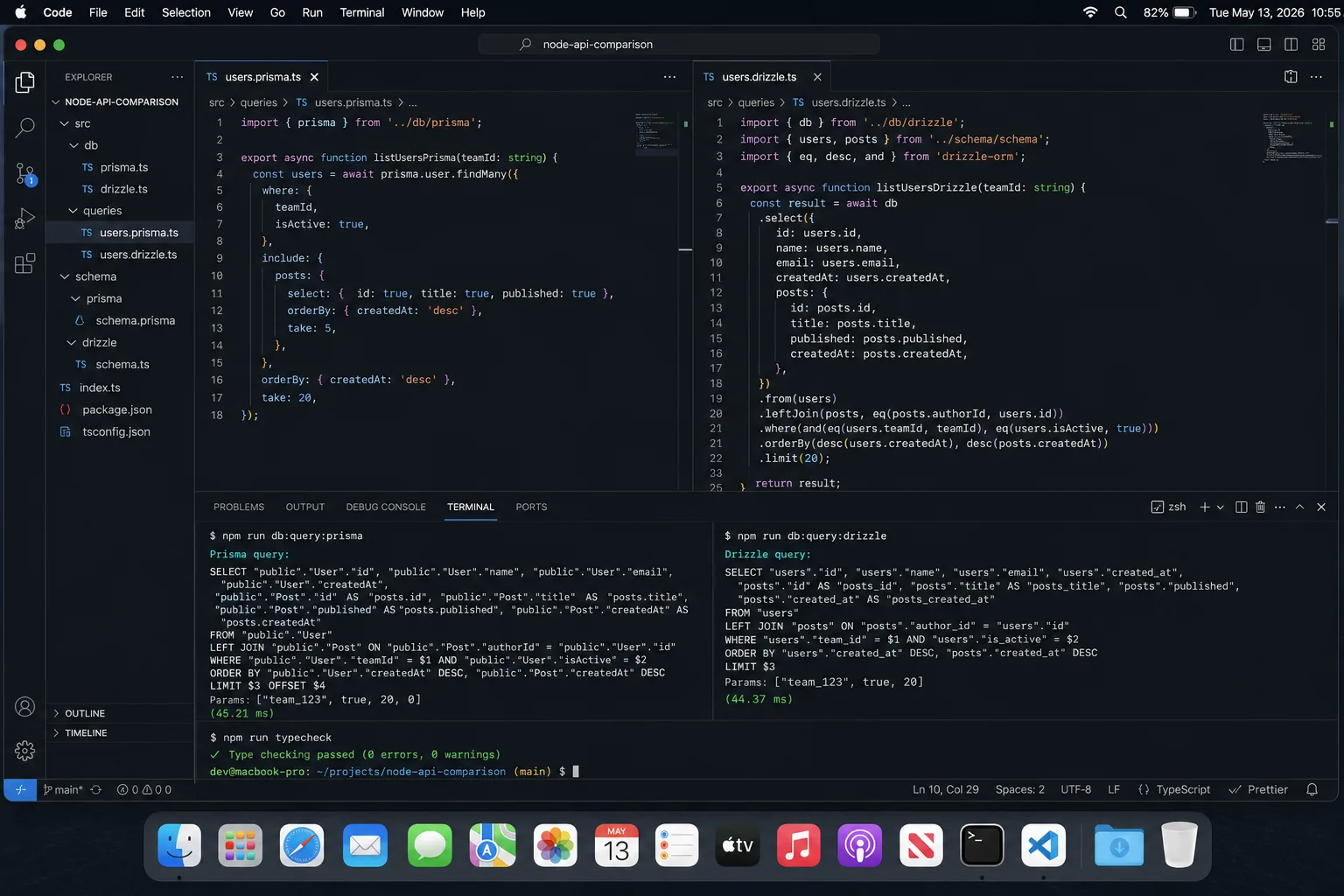
Side-by-side: how the same query looks in each
A typed query that fetches the latest 20 published posts with their author. This is closer to what real handlers do.
// Prisma
const posts = await db.post.findMany({
where: { status: 'PUBLISHED' },
orderBy: { publishedAt: 'desc' },
take: 20,
select: {
id: true,
title: true,
publishedAt: true,
author: { select: { id: true, email: true } },
},
});// Drizzle (SQL-first API)
import { eq, desc } from 'drizzle-orm';
import { db, posts, users } from './schema';
const rows = await db
.select({
id: posts.id,
title: posts.title,
publishedAt: posts.publishedAt,
author: { id: users.id, email: users.email },
})
.from(posts)
.innerJoin(users, eq(posts.authorId, users.id))
.where(eq(posts.status, 'PUBLISHED'))
.orderBy(desc(posts.publishedAt))
.limit(20);// Drizzle (relational query API — feels more like Prisma)
const rows = await db.query.posts.findMany({
where: eq(posts.status, 'PUBLISHED'),
orderBy: desc(posts.publishedAt),
limit: 20,
with: {
author: { columns: { id: true, email: true } },
},
});Drizzle gives you two APIs: a SQL-like one and a relational one that feels like Prisma. The relational API is useful for teams transitioning from Prisma; the SQL-like API is what you reach for when you need a GROUP BY or window function.
Complex queries: where the philosophies really diverge
“Find all published posts from users who signed up in the last 30 days, ordered by post count, with pagination.”
// Prisma
const results = await prisma.user.findMany({
where: {
createdAt: { gte: thirtyDaysAgo },
posts: { some: { published: true } },
},
include: {
posts: { where: { published: true }, orderBy: { createdAt: 'desc' } },
_count: { select: { posts: true } },
},
orderBy: { posts: { _count: 'desc' } },
skip: page * pageSize,
take: pageSize,
});// Drizzle
const results = await db
.select({
user: users,
postCount: sql<number>`count(${posts.id})`.as('post_count'),
})
.from(users)
.leftJoin(posts, and(
eq(posts.authorId, users.id),
eq(posts.published, true),
))
.where(gte(users.createdAt, thirtyDaysAgo))
.groupBy(users.id)
.orderBy(desc(sql`post_count`))
.limit(pageSize)
.offset(page * pageSize);Prisma’s query is more abstract — “find users where posts are published.” Drizzle’s maps to the SQL you’d write. If you know SQL, Drizzle is readable immediately. If you don’t, Prisma’s abstraction hides complexity that would otherwise require learning GROUP BY, LEFT JOIN, and aggregates.
Raw SQL escape hatch: typed vs untyped
Both ORMs let you drop to raw SQL. The experience is different:
// Prisma $queryRaw — return type is 'unknown', you lose type safety
const result = await prisma.$queryRaw`
SELECT u.*, COUNT(p.id) as post_count
FROM "User" u
LEFT JOIN "Post" p ON p."authorId" = u.id
WHERE p.published = true
GROUP BY u.id
`;// Drizzle sql template tag — table/column references stay type-checked
const result = await db.execute(sql`
SELECT ${users.id}, ${users.email}, COUNT(${posts.id}) as post_count
FROM ${users}
LEFT JOIN ${posts} ON ${posts.authorId} = ${users.id}
WHERE ${posts.published} = true
GROUP BY ${users.id}
`);Drizzle’s sql template tag lets you reference schema objects inside raw SQL, keeping partial type safety on column references. Prisma’s $queryRaw is fully untyped — you get back unknown[]. On complex reporting queries where you need raw SQL anyway, Drizzle’s approach is meaningfully safer.
Schema definition: file format vs TypeScript
Prisma uses its own schema language with a separate file:
// prisma/schema.prisma
model Post {
id String @id @default(cuid())
authorId String
title String
status PostStatus @default(DRAFT)
publishedAt DateTime?
author User @relation(fields: [authorId], references: [id])
@@index([status, publishedAt(sort: Desc)])
}
enum PostStatus {
DRAFT
PUBLISHED
ARCHIVED
}Drizzle uses TypeScript:
// src/schema.ts
import { pgTable, text, timestamp, pgEnum, index } from 'drizzle-orm/pg-core';
import { createId } from '@paralleldrive/cuid2';
export const postStatus = pgEnum('post_status', ['DRAFT', 'PUBLISHED', 'ARCHIVED']);
export const posts = pgTable(
'Post',
{
id: text('id').primaryKey().$defaultFn(() => createId()),
authorId: text('authorId').notNull().references(() => users.id),
title: text('title').notNull(),
status: postStatus('status').default('DRAFT').notNull(),
publishedAt: timestamp('publishedAt'),
},
(table) => ({
statusPubAt: index('Post_status_publishedAt_idx').on(table.status, table.publishedAt.desc()),
})
);Honest take: Prisma’s schema language is friendlier on day one. Drizzle’s TypeScript schema is friendlier on day 100 — refactor with grep, autocomplete on column names, and no two-language context switch. Pick by what you’ll do more of.
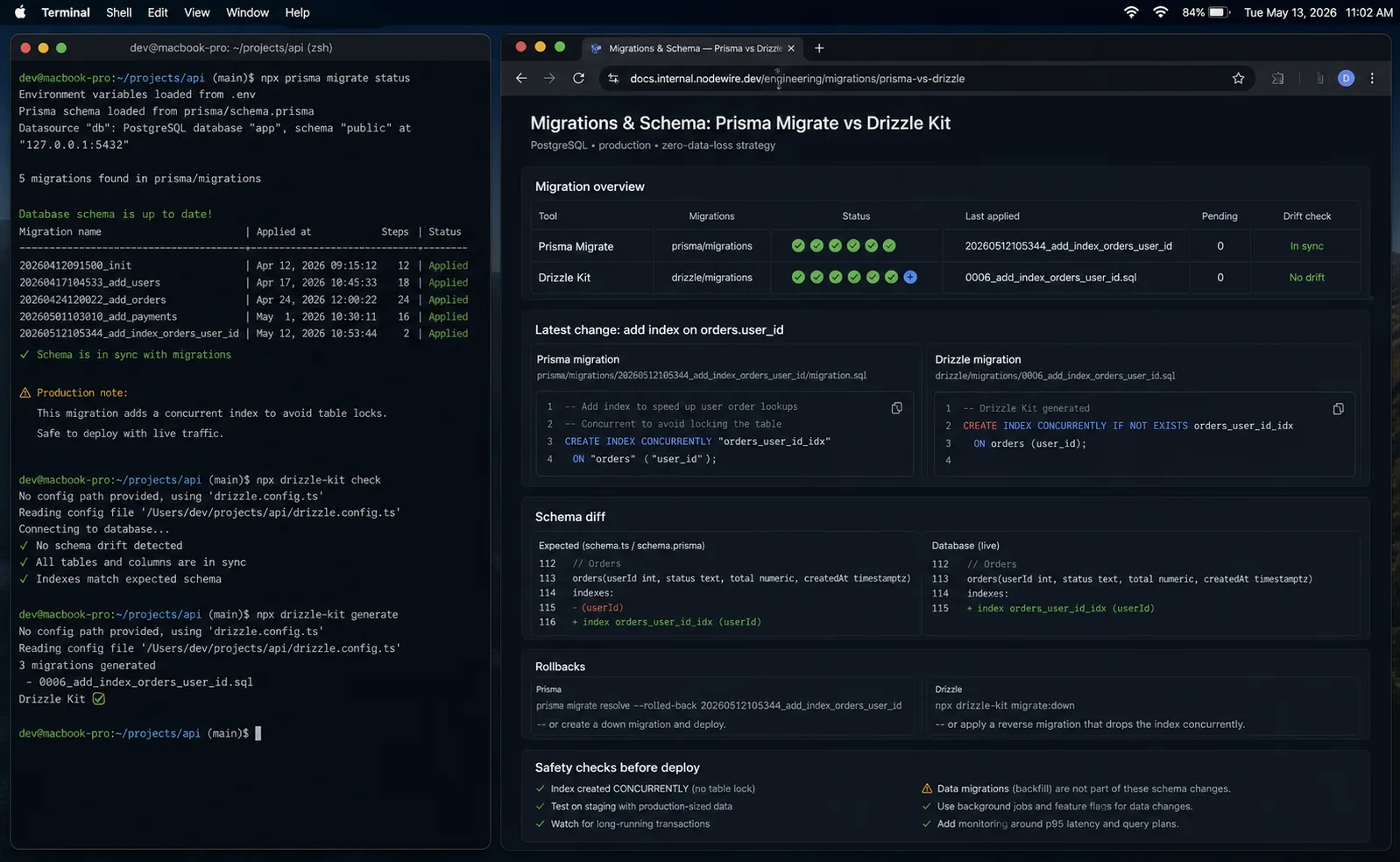
Migrations: where Prisma still leads
This is the gap Drizzle is closing but hasn’t closed yet.
| Aspect | Prisma | Drizzle |
|---|---|---|
| Generate migration from schema diff | prisma migrate dev |
drizzle-kit generate |
| Apply pending migrations | prisma migrate deploy |
drizzle-kit migrate or custom runner |
| Push schema without migration file (dev) | prisma db push |
drizzle-kit push |
| Shadow database for diff | Built-in, automatic | Not required (different diff strategy) |
| Migration history table | _prisma_migrations with checksum |
__drizzle_migrations |
| Custom data migration step | Edit generated SQL by hand | Edit generated SQL by hand |
| Rollback support | None (forward-only) | None (forward-only) |
| Schema drift detection | prisma migrate diff |
drizzle-kit check |
Both are forward-only. Both expect you to deploy a corrective migration if you need to undo something. Prisma’s tooling is more polished with better data loss detection and interactive prompts; Drizzle’s is faster and simpler. Drizzle also has a push mode that applies schema changes directly without generating a migration file — useful for rapid prototyping, dangerous in production.
Type safety: both win, in different ways
Prisma generates a typed client from your schema:
const post = await db.post.findUnique({ where: { id: '...' } });
// ^? Post | null — types come from the generated client
// Prisma also generates nested input types automatically:
type PostCreateInput = {
title: string;
author: UserCreateNestedOneWithoutPostsInput;
// ...Prisma creates these complex nested types for you
};Drizzle infers types from your schema definition at compile time:
type Post = typeof posts.$inferSelect; // inferred from the schema literal
type NewPost = typeof posts.$inferInsert; // separate type for inserts
// Types update the moment you save schema.ts — no generation step neededThe Drizzle approach has zero generation step — types are always current because they’re inferred from source code. The Prisma approach auto-generates complex nested relation input types that you’d have to write manually in Drizzle. One stale npx prisma generate away from confusing TypeScript errors — most teams add it to postinstall to avoid this. Prisma 7’s type checking is 70% faster, so the codegen step is less annoying than it was.
Business model: what you should know
This section usually gets skipped. It shouldn’t.
Prisma is a venture-funded company. The free ORM drives adoption for paid products: Prisma Accelerate (connection pooling + caching), Prisma Optimize (query analysis), and Prisma Postgres (managed database). This isn’t inherently bad — it’s how many successful open-source companies operate. But it means Prisma’s roadmap is influenced by commercial priorities. The move to the TS engine in Prisma 7 made Accelerate less of a requirement for serverless — which is a genuinely customer-friendly call that cost them some upsell surface area.
Drizzle ORM is open-source, maintained by the Drizzle Team, with Drizzle Studio as a commercial product. The ORM core has no feature gating. The project is charging toward 1.0 (v1.0.0-beta.22 as of April 2026), with the new migration system as the headline feature. No formal corporate backing means you’re relying on the team’s continued interest — though two years of stable v0.x releases with clear migration notes suggest this isn’t an immediate concern.
Migration path: Prisma to Drizzle without a rewrite
The smart way to move is incremental — exactly the same shape as the Express to Fastify migration. Both ORMs can talk to the same Postgres at the same time. Three rules I follow:
- Generate the Drizzle schema from your existing database with
drizzle-kit introspect(ordrizzle-kit pullin newer versions). Saves a day of typing, catches subtle mismatches between Prisma’s mental model and reality. - Migrate one repository file at a time, starting with the read-heavy hot endpoints. The repository pattern is what makes this possible — services don’t care which ORM the repo uses.
- Keep Prisma’s migration tool for schema changes during the transition. Drizzle reads any schema; you don’t need to migrate the migration toolchain on day one.
npm install drizzle-orm @paralleldrive/cuid2
npm install -D drizzle-kit
# Generate Drizzle schema from your existing Postgres (introspect the live DB)
npx drizzle-kit introspect --connectionString $DATABASE_URL --out ./src/db
# Or if using newer drizzle-kit:
npx drizzle-kit pull --connectionString $DATABASE_URL --out ./src/dbConnection pooling: same problem, different shape
Both ORMs hit the same Postgres limitations. The pooling story is identical:
| Topology | Prisma | Drizzle (with postgres.js) |
|---|---|---|
| Single VM | ?connection_limit=10 |
postgres(url, { max: 10 }) |
| Serverless | Prisma 7 native edge support, or Accelerate | Native HTTP driver (Neon, Supabase) or PgBouncer |
| PgBouncer transaction mode | ?pgbouncer=true (disables prepared statements) |
postgres(url, { prepare: false }) |
The Drizzle/postgres.js combination wins on serverless because postgres.js has first-class support for Neon’s HTTP driver and similar — connectionless query semantics, no pool exhaustion possible. With Prisma 7, you no longer need Accelerate just to avoid cold start penalties, but Drizzle still edges out on pure pool efficiency at the connection level.
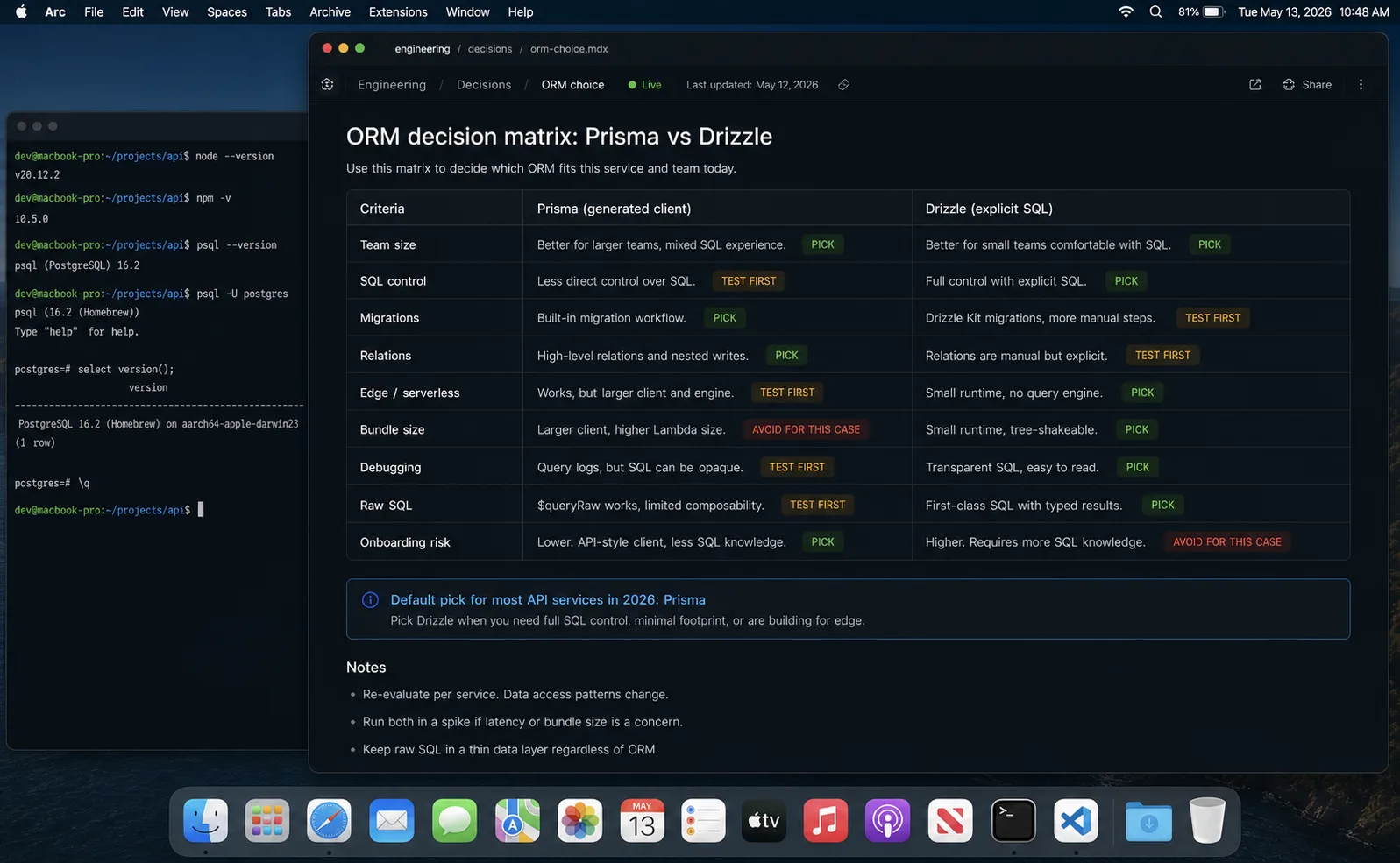
Decision matrix: which one to pick
| Pick Prisma when | Pick Drizzle when |
|---|---|
| Your team thinks in objects, not SQL. | Your team thinks in SQL. |
| You value polished migration tooling with data-loss detection. | You want to ship without a generation step. |
| Junior engineers will work in the codebase. | You write performance-sensitive queries by hand. |
| You want auto-generated nested relation input types. | You need the smallest possible runtime bundle. |
| You use Studio (Prisma’s GUI) for data inspection. | You deploy to Cloudflare Workers with strict size limits. |
| You need MongoDB or less common database support. | You want zero code generation in your build pipeline. |
| You use Prisma Accelerate/Optimize/Postgres ecosystem. | You want partial type safety in raw SQL escape hatches. |
Production checklist when you commit to Drizzle
- Use postgres.js as the underlying driver.
node-postgresworks but is slower; postgres.js is the recommended default. - Generate types from the schema literal, not from a separate file.
typeof table.$inferSelectstays in sync automatically. - Set the pool size explicitly —
postgres(url, { max: 10 }). The driver default is 10 but make it visible. - Composite indexes on the actual access pattern. Same rule as Prisma; same SQL underneath.
- Use
db.transaction(async (tx) => { ... })for multi-step writes. Drizzle’s transaction API mirrors Prisma’s. - Wrap data access in repositories, service code never imports Drizzle directly. Same pattern as Prisma — it pays off when you swap layers.
- Run
drizzle-kit checkin CI to catch schema drift between code and database. - Pin to 0.45.x in production if on v0. Drizzle 1.0 is in beta; track it in a side branch and migrate when it’s stable.
When not to use either
Three cases where the right answer is something else:
- Heavy analytics or reporting workloads. Both ORMs add overhead. Use postgres.js directly with hand-written SQL. The 7 ms overhead per query becomes meaningful when you run 10,000 queries per report.
- You ship to a database that isn’t Postgres or MySQL. Drizzle’s MS SQL / Oracle support is community-maintained at best. Prisma supports more dialects with better driver quality.
- You need a NoSQL store. Both are SQL ORMs. For Mongo or DynamoDB, look at the official drivers or Typegoose and Dynamoose respectively.
Troubleshooting FAQ
Is Drizzle production-ready in 2026?
Yes — with one caveat. The stable v0.x line (currently 0.45.2) has been running production workloads for two years. Drizzle 1.0 is in active beta (v1.0.0-beta.22 as of April 16, 2026), bringing a redesigned migration system; pin to 0.45.x in production and track 1.0 in a side branch. The library powers production traffic at companies including Anthropic and a long list of smaller shops.
Did Prisma 7 fix the cold start problem?
Mostly yes. The old Rust engine took 500–1,500 ms to initialize on Lambda. The new TS/WASM engine takes 40–80 ms. Drizzle still wins (20–50 ms), but the gap is now 50–80 ms rather than a full second. For most serverless workloads, Prisma 7 is no longer a dealbreaker.
Can I use Prisma and Drizzle in the same app?
Yes, against the same database. Useful during migration. Not a long-term plan — two ORMs is twice the surface area for bugs.
What about Kysely?
Kysely is a typed SQL query builder, similar to Drizzle but lower-level. Pick Kysely if you want Drizzle’s type safety without the ORM-shaped abstraction. Real choice between the two comes down to which API you find clearer.
Does Drizzle have a Studio equivalent?
Yes. drizzle-kit studio opens a local web UI for browsing data. Less polished than Prisma Studio but functional.
Which has better TypeScript performance in large codebases?
Drizzle, by a small margin. Prisma’s generated client gets large and tsserver gets slow on huge schemas. Drizzle’s inference is lazy — only what you query gets typed. Prisma 7’s 70% type-checking speedup closed the gap but didn’t reverse it.
Does Drizzle support read replicas?
Indirectly. You instantiate a separate Drizzle client pointed at the read replica connection string and route reads through it. Same approach as Prisma, no library magic in either case.
What about edge runtimes (Cloudflare Workers, Vercel Edge)?
Drizzle has a size advantage — 12 KB runtime vs Prisma 7’s 1.6 MB. Both technically work on Cloudflare Workers now (Prisma 7 removed the Rust binary requirement). In size-constrained edge environments, Drizzle’s headroom is meaningfully larger.
Should I switch from Prisma to Drizzle right now?
Probably not. The migration cost rarely pays back unless you have a measured performance problem with Prisma. Stay on Prisma; pick Drizzle for new projects where the trade-offs fit; consider migration only if you hit the same Prisma pain three times in three months.
Verdict
For new TypeScript-first backends in 2026, Drizzle is my default. Type-safe SQL with no codegen step, lower ORM overhead, and an edge-friendly story — and the sql template tag keeps type safety even in raw SQL queries, which Prisma can’t match.
For existing Prisma codebases that ship and earn, the migration cost rarely justifies itself. Prisma 7 has fixed most of the performance arguments that used to be compelling reasons to switch. Stay; pick Drizzle for the next service.
The wrong question is “which is better?” The right question is “what does my team already think in, what is my deployment shape, and what happens to my bundle size on Cloudflare Workers?”