
I helped a logistics startup split a Node.js monolith into seven services in 2022 and watched them spend the next eight months untangling a distributed monolith. The services shared the same Postgres, called each other synchronously, and a single deploy required coordinating four teams. Performance was worse than the monolith. Reliability was worse than the monolith. The bug surface was three times larger. Node.js microservices architecture works — I run it on three production systems right now — but only when you pick it for the right reasons and avoid the patterns that look right and aren’t.
This is the playbook I use now, with the heuristics that decide whether to start at all, the patterns that survive a pager rotation, and the failure modes I have personally caused.
The honest test: should you have microservices?
Three questions. If you answer “no” to any of them, stay on a monolith.
- Do you have multiple teams that need to deploy independently of each other? If one team can ship the entire system, microservices are paying you nothing back for the operational cost.
- Do different parts of the system have genuinely different scaling characteristics? If your image-processing endpoint needs 16 cores and your metadata API runs fine on 1, splitting them lets you scale each independently. If everything scales together, a single service with PM2 cluster mode is simpler and cheaper.
- Can you give each service its own data store? The instant two services share a database, you have made a distributed monolith. Schema migrations now require deploys in the right order. The “loose coupling” you bought is a fiction.
The logistics rebuild failed all three. They had one team. The services scaled identically. They shared the same Postgres. We rolled it back to a modular monolith and shipped twice as much for the next year.
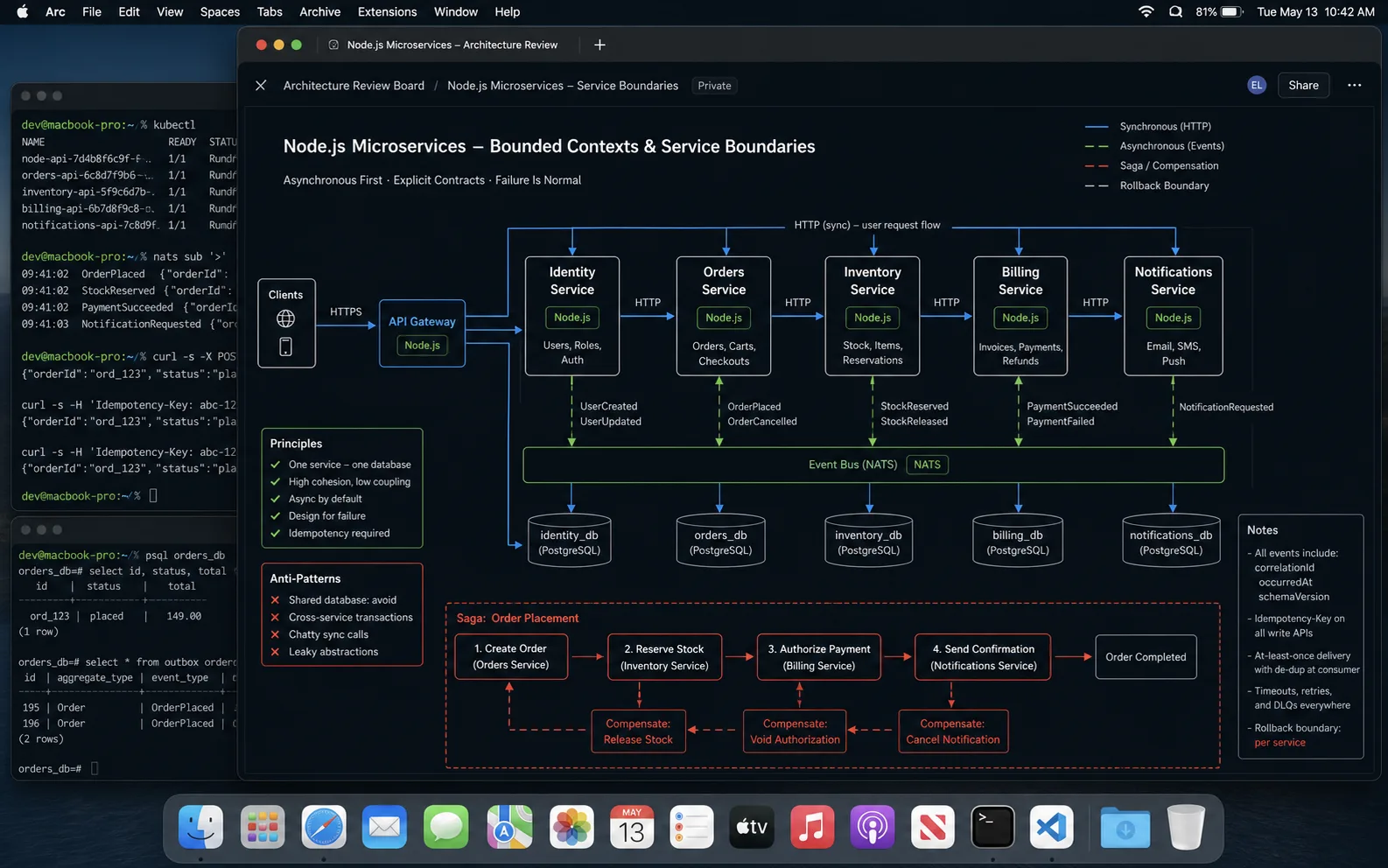
Service boundaries (the hard part)
The single biggest decision in microservices is where to draw the lines. Wrong cuts produce services that are constantly calling each other. Right cuts produce services that own a coherent business capability and rarely need data from elsewhere.
Two heuristics that work:
- Domain-driven bounded contexts. Identify the parts of your system that are independently understood by different stakeholders. “Inventory” is a context. “Billing” is a context. “Order processing” might be one or two depending on your business. Eric Evans’ bounded context framing remains the best mental model 20 years on.
- Data ownership. If two services would write to the same table, they should be one service. If they only ever read each other’s data through a clear API, they can be separate.
The cuts I made for the e-commerce client that worked: catalog-service (products + categories + inventory), orders-service (orders + carts), payments-service (transactions + refunds), users-service (accounts + auth + profile), notifications-service (email + SMS dispatch). Five services, each with its own database, talking through events for cross-cutting workflows. The system has been running for two years with each team owning two services.
What an “orders” service actually looks like in a Fastify + Prisma stack — minimal, but everything you need to deploy: Prisma client, request validation, structured logging via pino, healthcheck plus readiness probe, graceful shutdown, OpenTelemetry auto-instrumentation:
// services/orders/src/server.ts
import "./otel"; // import first — wires auto-instrumentation
import Fastify from "fastify";
import { PrismaClient } from "@prisma/client";
import { z } from "zod";
import { publish } from "@app/event-bus";
const prisma = new PrismaClient({ log: ["warn", "error"] });
const app = Fastify({
logger: { level: process.env.LOG_LEVEL ?? "info" },
requestIdHeader: "x-request-id",
genReqId: () => crypto.randomUUID(),
});
const CreateOrder = z.object({
customerId: z.string().uuid(),
items: z.array(z.object({
sku: z.string(),
qty: z.number().int().positive(),
})).min(1),
}).strict();
app.post("/orders", async (req, reply) => {
const body = CreateOrder.parse(req.body);
const order = await prisma.order.create({
data: { ...body, status: "PENDING" },
include: { items: true },
});
await publish("orders.created", { id: order.id, total: order.total });
return reply.code(201).send(order);
});
app.get("/orders/:id", async (req) => {
const { id } = req.params as { id: string };
return prisma.order.findUniqueOrThrow({ where: { id } });
});
// Liveness — process is up
app.get("/healthz", async () => ({ ok: true }));
// Readiness — can we actually serve traffic? (DB and broker are reachable)
app.get("/readyz", async (_req, reply) => {
try {
await prisma.$queryRaw`SELECT 1`;
return { ok: true };
} catch {
return reply.code(503).send({ ok: false });
}
});
const shutdown = async () => {
app.log.info("shutting down");
await app.close();
await prisma.$disconnect();
process.exit(0);
};
process.on("SIGTERM", shutdown);
process.on("SIGINT", shutdown);
await app.listen({ port: 3001, host: "0.0.0.0" });Two endpoints worth calling out. /healthz is liveness — Kubernetes restarts the pod if this fails. /readyz is readiness — Kubernetes pulls the pod from the load-balancer rotation if this fails, but does not restart it. Conflating them is the most common health-check bug I see; a transient DB blip should not restart the process, just hold traffic until it recovers.
Synchronous vs asynchronous communication
Two failure modes, opposite causes:
- Too much synchronous communication — services calling services in a chain.
orderscallsuserscallsauthcallsroles. One slow service stalls the entire request. One down service breaks the whole flow. - Too much asynchronous communication — every action emits an event, every service consumes a dozen event types. The system is impossible to reason about; debugging a failed order means tracing six event handlers across four services.
The rule I use:
- Synchronous (HTTP/gRPC) for queries that need fresh data and are part of an interactive request.
GET /orders/:idcallsusers-servicefor the customer details — fine, it is a read, the latency is paid by one user. - Asynchronous (events) for cross-service workflows. When an order is placed,
orders-serviceemits anOrderPlacedevent.payments-service,notifications-service, andanalytics-serviceall consume it independently.orders-servicedoes not know who is listening. For Node-only systems with low operational tolerance for a broker, a Redis-backed queue (BullMQ) covers the same use cases.
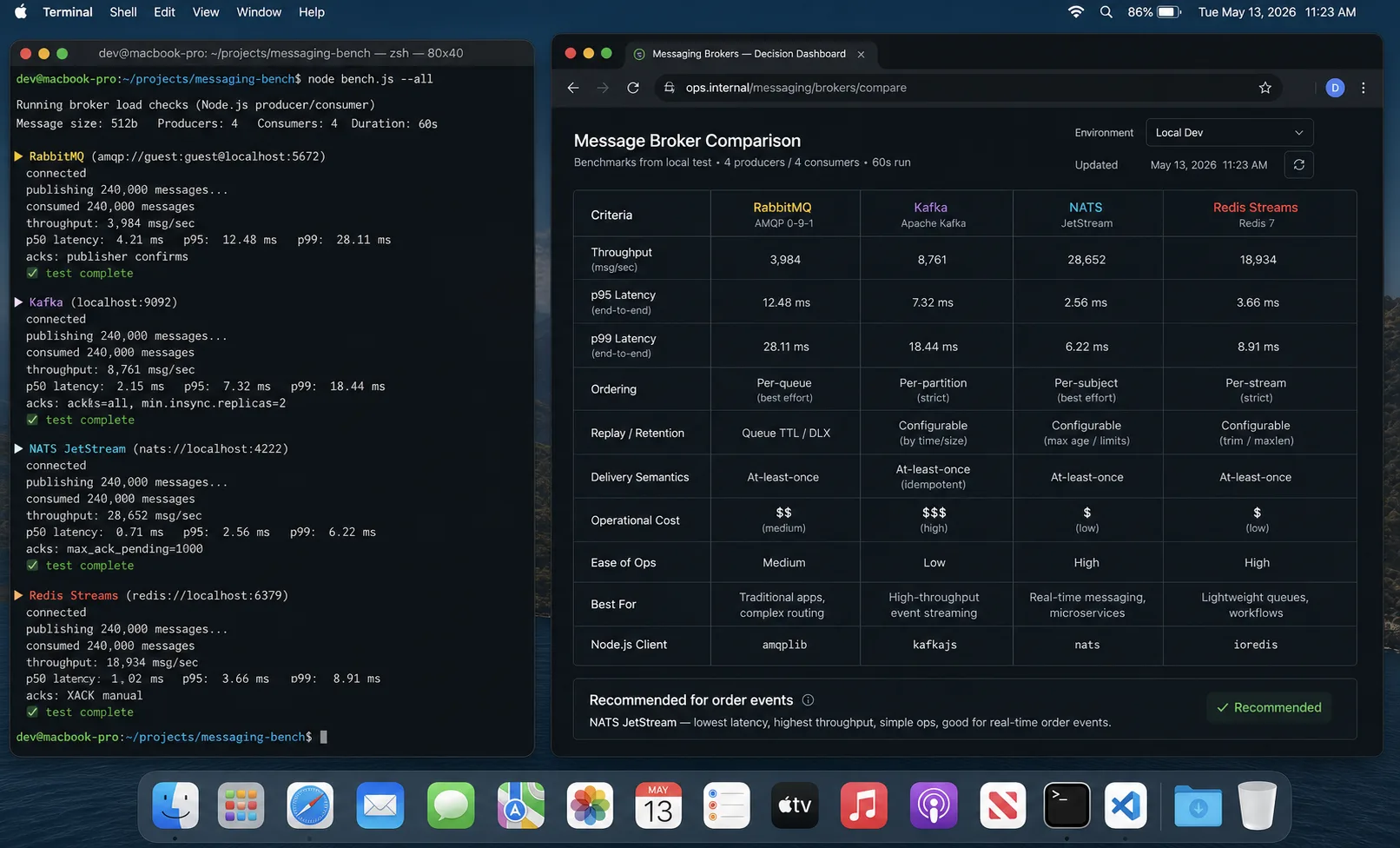
The messaging backbone: RabbitMQ vs Kafka vs NATS vs Redis Streams
| RabbitMQ 4.x | Kafka 3.7 | NATS JetStream | Redis Streams | |
|---|---|---|---|---|
| Throughput | ~50k msg/s | 1M+ msg/s | ~500k msg/s | ~200k msg/s |
| p99 latency | ~5 ms | ~10 ms | ~1 ms | ~1 ms |
| Ordering | Per-queue | Per-partition | Per-subject | Per-stream |
| Retention | Until acked | Time- or size-based | Configurable | Time- or size-based |
| Replay | No | Yes (full log) | Yes (last N + age) | Yes (within retention) |
| Best for | Task queues, RPC | Event streams, replay, analytics | Low-latency pub/sub + persistence | Lightweight queues |
| Operational complexity | Low | High | Low | Very low |
| Node.js client | amqplib | kafkajs | nats | ioredis |
For most Node.js microservice systems, RabbitMQ 4.x is enough. Kafka pays back when you actually need event sourcing, replay across many consumer groups, or genuinely high throughput for analytics pipelines. NATS JetStream is the dark-horse pick for low-latency systems where you want a single binary instead of a Java cluster. Redis Streams works well when your team already runs Redis and you want a queue without standing up a new piece of infrastructure.
I have shipped on all four. RabbitMQ is the one I would default to for a 5-service system. amqplib for Node, mature, boring, works.
Decision matrix: which broker for which workload
| Workload | Pick | Why |
|---|---|---|
| 5 services, mostly task queues + simple events | RabbitMQ 4.x | Mature, low ops, classic + quorum queues, dead-letter exchanges |
| Event sourcing, audit log, analytics replay | Kafka 3.7 | Durable log, replay across consumer groups, ecosystem |
| Low-latency pub/sub with persistence, single binary | NATS JetStream | Sub-ms latency, simple ops, durable streams |
| Already running Redis, modest throughput | Redis Streams + BullMQ | One less moving part, good Node ecosystem |
| Serverless / managed-only | AWS SQS + SNS or GCP Pub/Sub | No broker to operate; trade ops for vendor lock-in |
| Real-time push to browsers | Out of scope for the broker | Use Socket.IO with the Redis adapter — see the WebSockets guide |
The event bus (typed, validated, easy to add events to)
The publish/subscribe glue using NATS JetStream for durable delivery — every service imports the same tiny module, so adding a new event type is one line in the schema map and one subscriber. The schema map doubles as runtime validation:
// packages/event-bus/src/index.ts
import { connect, JSONCodec, jetstreamManager, JetStreamClient, NatsConnection } from "nats";
import { z } from "zod";
const Schemas = {
"orders.created": z.object({ id: z.string().uuid(), total: z.number() }),
"orders.cancelled": z.object({ id: z.string().uuid(), reason: z.string() }),
"payments.captured": z.object({ orderId: z.string().uuid(), amount: z.number() }),
} as const;
type EventName = keyof typeof Schemas;
const codec = JSONCodec();
let nc: NatsConnection | null = null;
let js: JetStreamClient | null = null;
export async function connectBus(servers = process.env.NATS_URL ?? "nats://localhost:4222") {
nc = await connect({ servers, name: process.env.SERVICE_NAME ?? "unknown" });
const jsm = await jetstreamManager(nc);
await jsm.streams.add({ name: "EVENTS", subjects: ["orders.>", "payments.>"] });
js = nc.jetstream();
}
export async function publish<K extends EventName>(name: K, payload: z.infer<typeof Schemas[K]>) {
if (!js) throw new Error("bus not connected");
Schemas[name].parse(payload); // fail fast on bad publish
await js.publish(name, codec.encode(payload));
}
export async function subscribe<K extends EventName>(
name: K,
durable: string,
handler: (payload: z.infer<typeof Schemas[K]>) => Promise<void>,
) {
if (!js) throw new Error("bus not connected");
const sub = await js.subscribe(name, { config: { durable_name: durable, ack_wait: 30_000 } });
for await (const m of sub) {
try {
const payload = Schemas[name].parse(codec.decode(m.data));
await handler(payload);
m.ack();
} catch (err) {
m.nak(5_000); // negative-ack with backoff; JetStream redelivers
console.error({ err, subject: name, durable }, "handler failed");
}
}
}Validating at both publish and consume time is the line that catches the worst class of bug — a producer ships a new version with an extra field, the consumer crashes on every message, and the queue backs up overnight. With validation, the producer’s deploy fails CI instead.
Idempotency is non-negotiable
RabbitMQ, Kafka, NATS, and Redis Streams all guarantee at-least-once delivery — never exactly-once. Your consumer will receive the same event twice. Sometimes it is a duplicate ack, sometimes a redelivery after a crash, sometimes a producer retry that succeeded the first time. Either way, the consumer must handle it.
The standard pattern: include an eventId in every payload, write a uniqueness constraint into the consumer’s database, and let the second insert fail harmlessly:
// payments-service consumer
await subscribe("orders.created", "payments-svc", async (event) => {
await db.$transaction(async (tx) => {
const exists = await tx.processedEvent.findUnique({ where: { id: event.id } });
if (exists) return; // already handled — short-circuit
await tx.processedEvent.create({ data: { id: event.id } });
await chargeCard(event);
});
});That eight-line pattern eliminates the “we charged the customer twice” class of bug for good. Pair it with a nightly cleanup of processedEvent rows older than your retention window so the table does not grow unbounded.
Dead letter queues (the place failed messages go to be inspected)
When a consumer fails and the queue redelivers a few times without success, you do not want it to retry forever — you want it parked somewhere a human can look at. RabbitMQ implements this via dead-letter exchanges:
// payments-service: bind queue with DLX configuration
const DLX = "payments.dlx";
const DLQ = "payments.dlq";
await ch.assertExchange(DLX, "direct", { durable: true });
await ch.assertQueue(DLQ, { durable: true });
await ch.bindQueue(DLQ, DLX, "dead");
await ch.assertQueue("payments.orders.created", {
durable: true,
arguments: {
"x-dead-letter-exchange": DLX,
"x-dead-letter-routing-key": "dead",
"x-delivery-limit": 5, // RabbitMQ 4.x quorum queues
},
});Five attempts, then the message goes to payments.dlq where on-call can inspect, fix the root cause, and replay. RabbitMQ 4.x’s quorum queues add the x-delivery-limit argument, which is cleaner than the manual retry-counter-in-headers dance you needed in 3.x. NATS JetStream has the same concept via max_deliver.
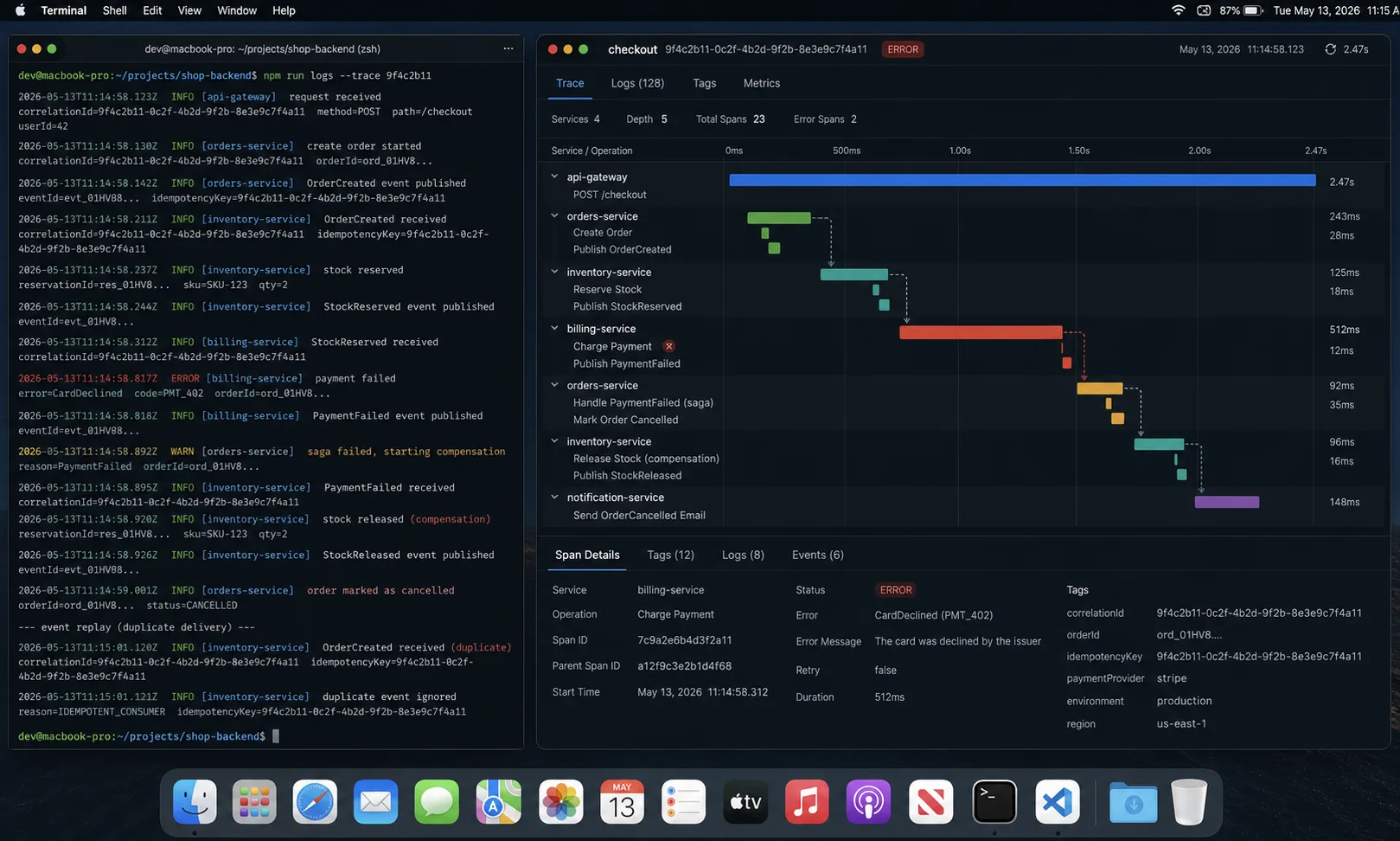
The saga pattern (when transactions cannot span services)
The classic example: placing an order requires reserving inventory, charging the card, and creating a shipment. In a monolith, that is one transaction. Across services, there is no atomicity — the card might charge after the inventory reservation fails.
The saga pattern: each step is its own transaction, with a compensating action on failure. If step 3 fails, you trigger compensations for steps 1 and 2.
// orders-service/place-order-saga.ts
import { eventBus } from "./events";
export async function placeOrder(input: OrderInput) {
const orderId = await db.order.create({ data: { ...input, status: "pending" } });
try {
await eventBus.request("inventory.reserve", { orderId, items: input.items });
await eventBus.request("payments.charge", { orderId, amount: input.total, paymentMethodId: input.paymentMethodId });
await eventBus.request("shipping.create", { orderId, address: input.address });
await db.order.update({ where: { id: orderId }, data: { status: "confirmed" } });
eventBus.emit("OrderConfirmed", { orderId });
return orderId;
} catch (err) {
// Compensating actions, in reverse order. Failures here are logged but do
// not throw — we have already failed the user, double-failing the cleanup
// makes things worse.
await eventBus.emit("payments.refund", { orderId }).catch(() => {});
await eventBus.emit("inventory.release", { orderId }).catch(() => {});
await db.order.update({ where: { id: orderId }, data: { status: "failed", failureReason: String(err) } });
eventBus.emit("OrderFailed", { orderId });
throw err;
}
}Two flavours: orchestration (one service runs the saga, calling others) and choreography (services react to each other’s events without a central coordinator). Orchestration is easier to debug because the flow lives in one file. Choreography scales to more services because no service knows the full shape. I have shipped both; orchestration is my default for sagas with five or fewer steps. Past that, choreography wins because the orchestrator becomes a god object.
Circuit breakers (so a slow downstream does not take you down)
Synchronous service calls inherit each other’s failure modes. If users-service is slow, every request that calls it stalls — your orders pod’s worker pool fills up with hung calls, then your readiness probe starts failing, then Kubernetes pulls you out of rotation. One downstream takes the cluster down.
A circuit breaker prevents the cascade. After N consecutive failures, the breaker “opens” — subsequent calls fail fast for a cooldown window, then a single test call probes whether the downstream has recovered. opossum is the standard Node implementation:
import CircuitBreaker from "opossum";
const fetchUser = (id: string) =>
fetch(`http://users:3000/users/${id}`).then((r) => r.json());
const breaker = new CircuitBreaker(fetchUser, {
timeout: 3_000,
errorThresholdPercentage: 50,
resetTimeout: 10_000,
rollingCountBuckets: 10,
});
breaker.fallback((id: string) => ({ id, name: "Unknown", _stale: true }));
breaker.on("open", () => logger.warn("users circuit OPEN"));
breaker.on("halfOpen", () => logger.info("users circuit HALF-OPEN"));
app.get("/orders/:id", async (req, reply) => {
const order = await db.order.findUniqueOrThrow({ where: { id: req.params.id } });
const user = await breaker.fire(order.customerId);
return { ...order, customer: user };
});The fallback returning a degraded user object beats throwing. The order detail page shows “Unknown customer” instead of a 500 — the user can still read their order, the metric you care about (5xx rate) stays clean, and the broken downstream gets time to recover without a thundering herd of retries.
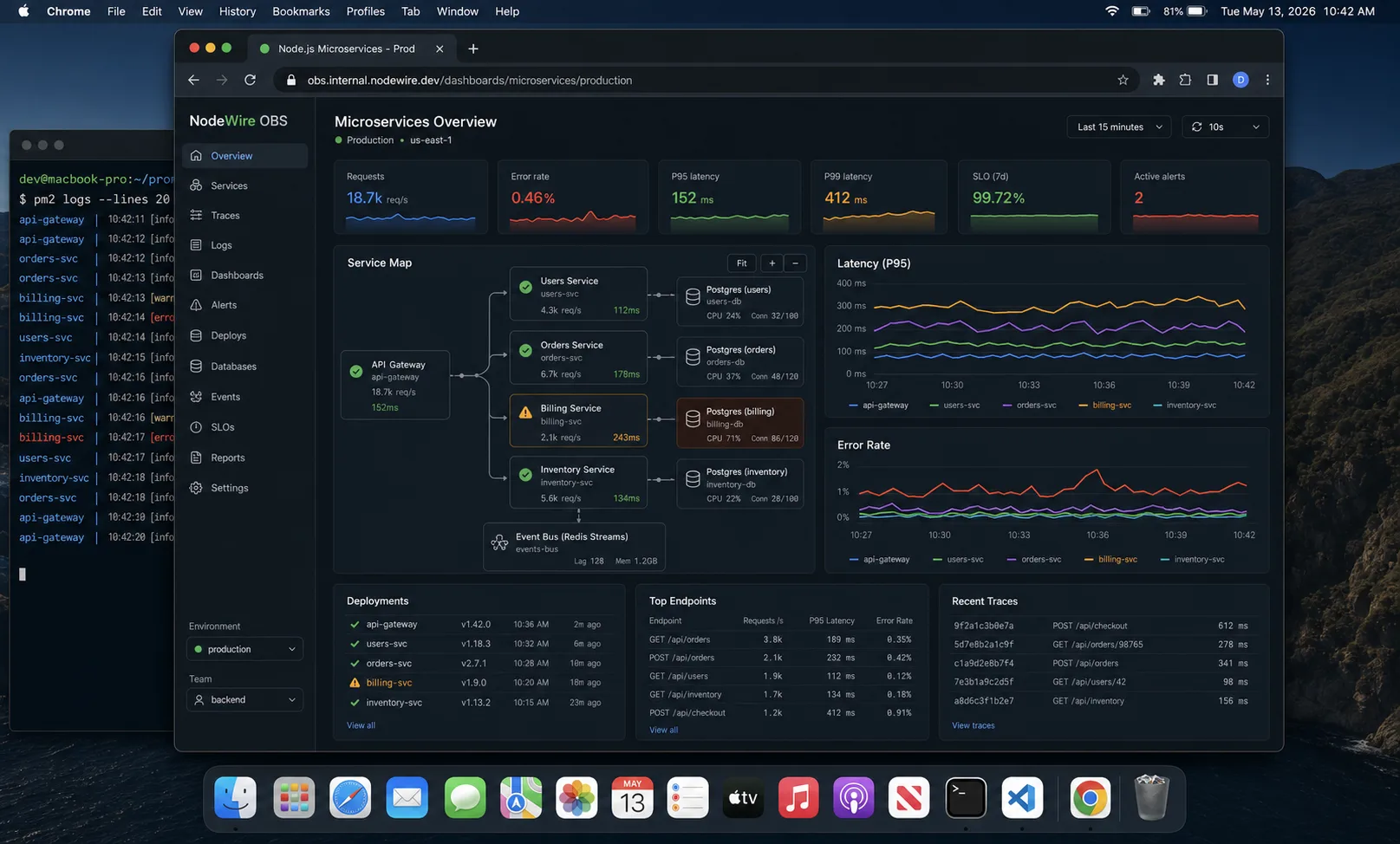
Observability (or your microservices are a black box)
The biggest cost of microservices is not operational — it is debugging. A request crosses 4 services, fails somewhere in the middle, and you have 4 separate log streams to correlate. Without distributed tracing, you are guessing.
Three things to wire up day one:
- Trace context propagation. A
traceparentheader on the inbound HTTP request, propagated to every downstream call, included in every log line. The OpenTelemetry SDK handles this with auto-instrumentation for Express/Fastify, HTTP clients, Postgres, Redis, amqplib, and NATS. You import a single bootstrap file at the top of your entry point and you get traces across the whole system. - Centralised structured logging. Pino to stdout, ship to Loki / Elasticsearch / Datadog. Filter by
trace-idto see the whole request across services. Logging patterns are in the Pino vs Winston comparison. - Service-level health and SLO dashboards. Each service exposes
/healthz(liveness) and/readyz(readiness). Dashboards show error rate, latency, throughput per service. Shared infrastructure (Redis for caching, locks, presence) deserves its own dashboard too — patterns in the Node.js Redis caching guide. Without these, you cannot tell which service is broken when something fails.
// services/orders/src/otel.ts — imported FIRST in server.ts
import { NodeSDK } from "@opentelemetry/sdk-node";
import { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-http";
import { Resource } from "@opentelemetry/resources";
import { SemanticResourceAttributes as SRA } from "@opentelemetry/semantic-conventions";
const sdk = new NodeSDK({
resource: new Resource({
[SRA.SERVICE_NAME]: process.env.SERVICE_NAME ?? "orders",
[SRA.SERVICE_VERSION]: process.env.GIT_SHA ?? "dev",
}),
traceExporter: new OTLPTraceExporter({ url: process.env.OTEL_ENDPOINT }),
instrumentations: [getNodeAutoInstrumentations()],
});
sdk.start();
process.on("SIGTERM", () => sdk.shutdown());That fifteen-line file gives you traces across HTTP, Prisma, ioredis, amqplib, and NATS without changing a single line of business code. OpenTelemetry hit GA in 2023; in 2026 the auto-instrumentation packages cover essentially every Node library you would use in a microservices stack.
The API gateway (one place to handle cross-cutting concerns)
Do not have every service implement auth, rate limiting, CORS, request logging, and TLS termination. Put a gateway in front. Three reasonable picks:
- Kong — full-featured, has a free OSS tier, ships with plugins for most needs.
- Traefik — Docker / Kubernetes-native, simpler config, less plugin ecosystem.
- nginx — the boring choice, hand-rolled config, lowest overhead.
For 3–5 services, nginx is plenty. Past that, Kong or Traefik for the management surface area. The nginx-as-gateway config (TLS termination, upstream pools, gzip) is in the DigitalOcean Node.js deployment guide.
For the Node-native option — gateway code that lives in your monorepo and shares your TypeScript types — a small Express or Fastify service with http-proxy-middleware works fine for 5–10 services. Auth (JWT validation) happens at the gateway; downstream services trust an internal x-user-id header. The full posture is in the Node.js API security checklist.
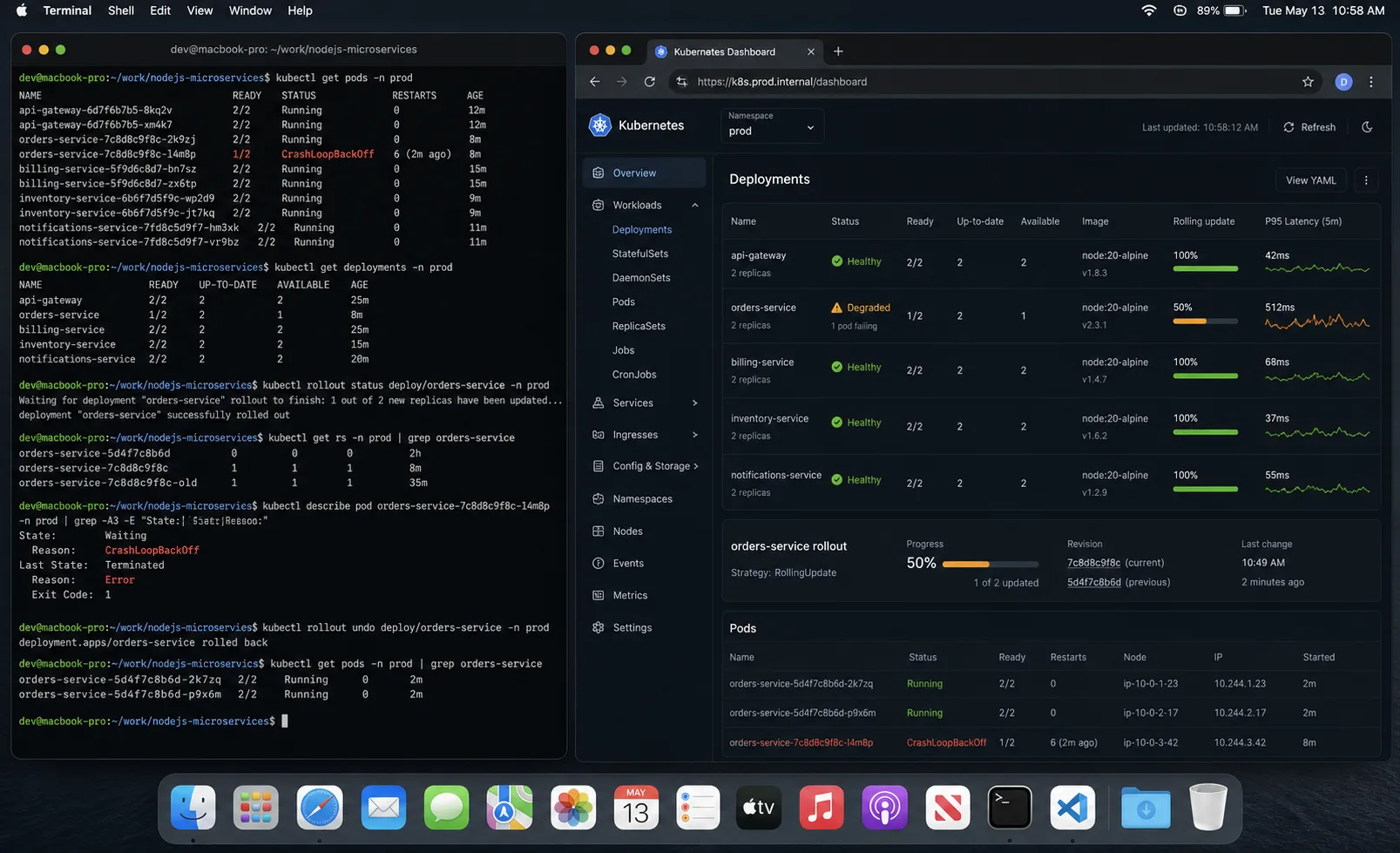
Deployment: container orchestration is the price of entry
Microservices and a manual deploy process are not compatible. You need:
- A container registry (GHCR, ECR, Docker Hub).
- An orchestrator (Kubernetes for big systems, Docker Swarm or Nomad for small, ECS for AWS-only).
- Per-service CI/CD pipelines that build, test, and deploy independently.
- A service discovery mechanism (Consul, Kubernetes DNS, NATS connect addresses).
If you are not ready for that operational layer, you are not ready for microservices. The Docker patterns are in the Node.js Docker guide; everything past that is orchestrator-specific.
Local-dev docker compose for the same three services + NATS + Postgres. This is the file I hand new engineers on day one — they clone the repo, run docker compose up, and hit the API on port 3000 within 90 seconds. Production runs the same images on Kubernetes, but compose is what keeps inner-loop dev fast:
# docker-compose.yml
services:
nats:
image: nats:2.10-alpine
command: ["-js", "-sd", "/data"]
ports: ["4222:4222"]
volumes: ["nats-data:/data"]
healthcheck:
test: ["CMD", "nats-server", "--healthz"]
interval: 10s
postgres:
image: postgres:18-alpine
environment:
POSTGRES_PASSWORD: dev
POSTGRES_DB: orders
ports: ["5432:5432"]
volumes: ["pg-data:/var/lib/postgresql/data"]
orders:
build: ./services/orders
environment:
DATABASE_URL: postgres://postgres:dev@postgres:5432/orders
NATS_URL: nats://nats:4222
SERVICE_NAME: orders
OTEL_ENDPOINT: http://otel-collector:4318/v1/traces
depends_on:
postgres: { condition: service_started }
nats: { condition: service_healthy }
ports: ["3001:3001"]
payments:
build: ./services/payments
environment:
NATS_URL: nats://nats:4222
SERVICE_NAME: payments
STRIPE_SECRET_KEY: ${STRIPE_SECRET_KEY}
depends_on: [nats]
ports: ["3002:3002"]
gateway:
build: ./services/gateway
environment:
ORDERS_URL: http://orders:3001
PAYMENTS_URL: http://payments:3002
NATS_URL: nats://nats:4222
depends_on: [orders, payments]
ports: ["3000:3000"]
volumes:
nats-data:
pg-data:When NOT to use microservices
- Single-team systems. Microservices solve organisational scaling problems. If you do not have an organisation to scale, you are paying the cost for nothing.
- Pre-product-market-fit startups. You do not know what the right service boundaries are because you do not know what your business is yet. Ship a monolith, learn, refactor.
- Systems that do not scale heterogeneously. If everything has the same load profile, scaling the whole monolith horizontally is simpler than micro-managing per-service replicas.
- Teams without observability investment. Without distributed tracing and centralised logs, microservices are a debugging nightmare.
- Teams without on-call rotations. Microservices fail in subtle, distributed-system ways. If nobody is paged when production breaks, the failures pile up silently.
The modular monolith — the option most teams should pick
Code organised as if it were microservices (clear modules, owned datasets per module, no cross-module imports of internals) but deployed as one binary. You get most of the architectural benefits — clear ownership, parallel work, easier reasoning — without the operational tax. When (if) you need to extract a true service, you have already done the hard work.
This is the architecture I recommend to ~70% of teams that ask about microservices. The 30% who genuinely need microservices know they need them; the rest get burned.
FAQ
How do I build microservices with Node.js?
Start with bounded contexts — identify parts of your system with distinct ownership and data. Each service gets its own database. Build on Node 24 LTS + Fastify + Prisma. Talk synchronously (HTTP, with circuit breakers via opossum) for interactive reads, asynchronously (events through RabbitMQ 4.x or NATS JetStream) for cross-service workflows. Wire up OpenTelemetry on day one or you will regret it on day 30. Validate every event payload at publish and consume time. Make consumers idempotent.
When should I use microservices vs a monolith?
Microservices when you have multiple teams that need independent deploys, parts of the system that scale very differently, and the operational maturity for container orchestration plus distributed tracing. Otherwise, a modular monolith is faster to build, simpler to debug, and cheaper to run. The “just in case we scale” reason is the wrong one — refactoring a clean modular monolith into services is the easy half of the journey.
RabbitMQ vs Kafka for Node.js — which one?
RabbitMQ 4.x for most systems — lower operational complexity, mature Node.js client (amqplib), enough throughput for under 50k msg/s, quorum queues with per-message delivery limits, built-in dead-letter exchanges. Kafka 3.7 when you need event sourcing, replay across many consumer groups, or genuinely high throughput for analytics pipelines. NATS JetStream is the dark-horse pick for low-latency pub/sub with persistence; Redis Streams when you already run Redis and want a queue without standing up a new piece of infrastructure.
What is the saga pattern?
A way to coordinate transactions across services that cannot share a database. Each step is a local transaction with a compensating action. On failure, you run the compensations in reverse order to leave the system in a consistent state. Two flavours: orchestration (one service runs the saga) and choreography (services react to each other’s events). Orchestration is easier to debug; choreography scales to more steps.
How do I handle authentication across microservices?
Validate the JWT once at the API gateway and pass the verified user context to downstream services in trusted internal headers (x-user-id, x-user-role). Each service trusts the gateway. Do not have every service hit the auth service on every request — that is a fan-out trap. Full token-handling rules (rotation, revocation, header hygiene) are on the Node.js API security checklist and the JWT authentication guide.
How do I prevent cascading failures across services?
Three layers. Wrap every cross-service HTTP call in a circuit breaker (opossum) with a sensible fallback. Set strict client-side timeouts on every fetch — defaults are infinite. Apply per-route bulkheads (limit the number of concurrent calls to any single downstream) so one slow downstream cannot consume your entire worker pool. The Express rate-limiting guide covers the bulkhead pattern using a Redis-backed semaphore.
How do I make consumers idempotent?
Include an eventId (UUID) in every event payload. The consumer’s database has a uniqueness constraint on a processed_event table. The handler is wrapped in a transaction that inserts the event ID first; if the insert fails on the unique constraint, the event has already been handled and the handler exits early. Eight lines of code, eliminates the “we charged the customer twice” class of bug for good.
What is the biggest mistake teams make with microservices?
Sharing a database. The moment two services write to the same table, you have a distributed monolith — all the operational cost of microservices, none of the loose-coupling benefits. Each service owns its data. Cross-service reads happen through APIs. The second-biggest mistake is shipping without distributed tracing; the third is letting individual services accumulate dozens of event subscriptions until nobody understands what an action triggers.
How do I deploy Node.js microservices?
Per-service Dockerfiles, a container registry, an orchestrator (Kubernetes is the default in 2026; ECS for AWS-only shops; Nomad if you have a strong reason). Each service has its own CI/CD pipeline that builds, tests, and deploys independently. Use Kubernetes liveness probes against /healthz and readiness probes against /readyz. The DigitalOcean deploy guide covers the single-VPS variant; the multi-service variant adds a Helm chart per service plus a shared chart for cross-cutting infrastructure (Redis, Postgres, NATS).