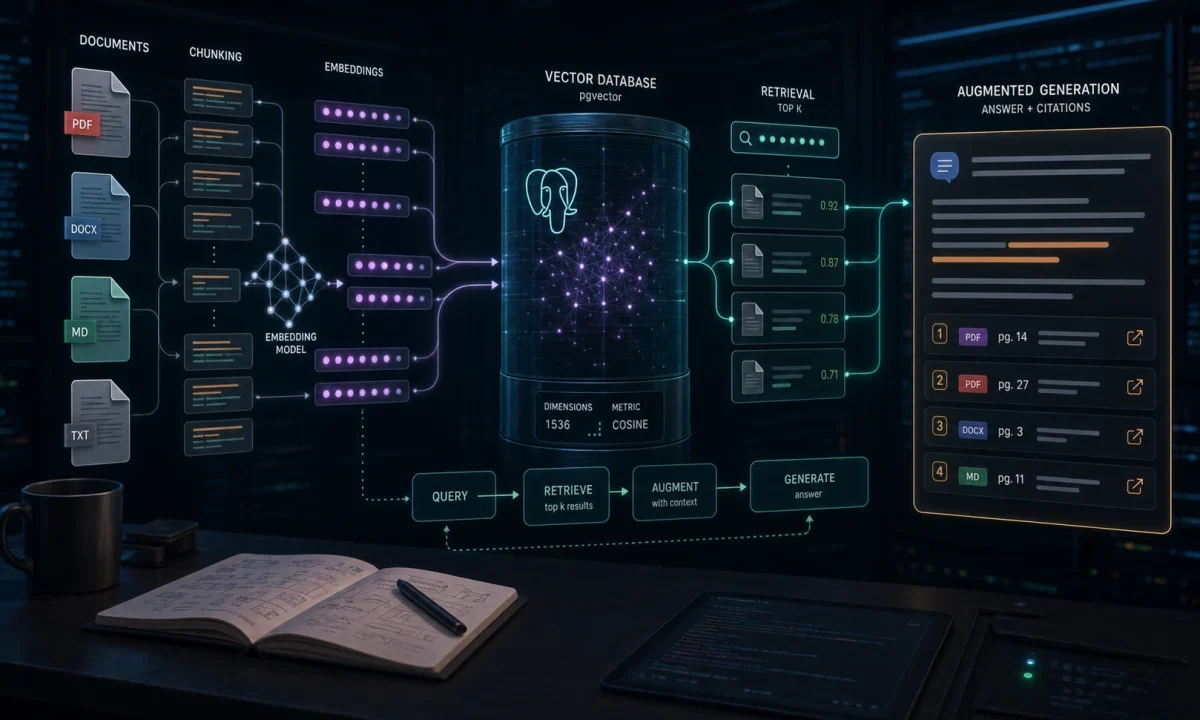
The first RAG system I shipped looked correct in demos and lied in production. The user asked for the refund policy. The app retrieved three chunks about shipping, one chunk from an old policy PDF, and answered with the confidence of a lawyer who had not read the contract. The model was not the main bug. Retrieval was.
A good RAG API in Node.js is less about sprinkling embeddings on documents and more about boring engineering: clean ingestion, stable chunk IDs, metadata filters, pgvector indexes, retrieval tests, citations, streaming, and refusal when the context does not support an answer. This is the setup I would ship today with Node.js 24 LTS, TypeScript, Postgres + pgvector, OpenAI embeddings, and the Responses API.
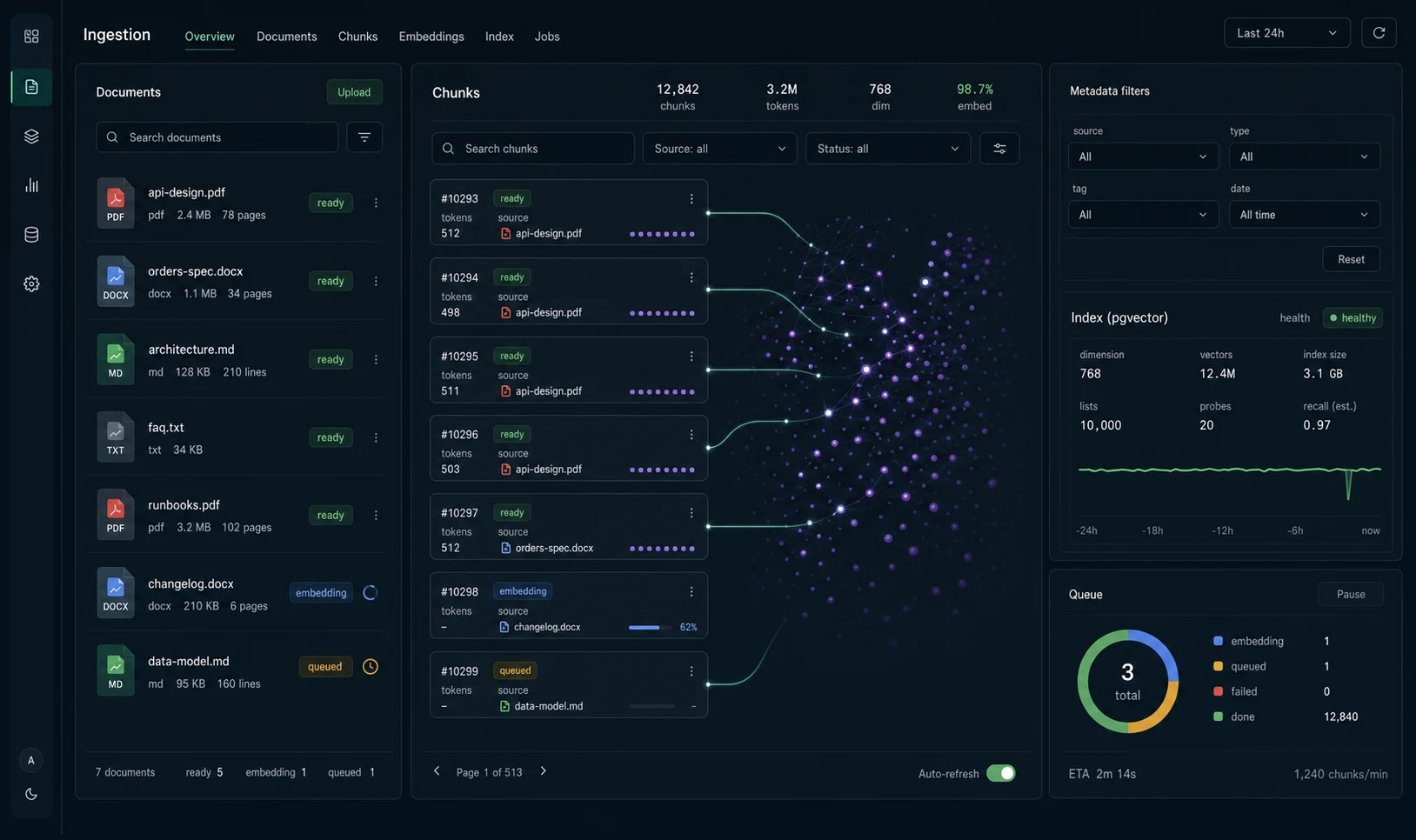
The architecture that keeps RAG from lying confidently
upload docs
-> parse text
-> split into chunks
-> embed chunks
-> store chunk + vector + metadata in Postgres
user question
-> embed question
-> vector search with metadata filters
-> build grounded prompt with citations
-> stream answer
-> log scores, cost, latencyThe OpenAI text-embedding-3-small model docs cover the embedding model I use here, including its text input/output shape and pricing. The pgvector README documents the vector column, cosine distance operator, HNSW indexes, and the speed/recall tradeoff you inherit once approximate search enters the stack. The model still only answers well if the right chunks land in context.
The install is easy; retrieval quality is not
npm i openai pg zod express
npm i -D typescript tsx @types/node @types/expressPostgres needs pgvector enabled:
create extension if not exists pgcrypto;
create extension if not exists vector;
create table documents (
id uuid primary key default gen_random_uuid(),
title text not null,
source_url text,
created_at timestamptz not null default now()
);
create table document_chunks (
id uuid primary key default gen_random_uuid(),
document_id uuid not null references documents(id) on delete cascade,
chunk_index int not null,
content text not null,
token_count int not null,
metadata jsonb not null default '{}',
embedding vector(1536) not null,
created_at timestamptz not null default now(),
unique(document_id, chunk_index)
);
create index document_chunks_embedding_idx
on document_chunks
using hnsw (embedding vector_cosine_ops);The 1536 dimension matches text-embedding-3-small. If you pick a different embedding model, match the vector dimension to that model. Do not make this a mystery constant hidden in migrations. I test this version on Node.js 24 LTS, current openai npm SDK, Postgres 16+, and pgvector with HNSW indexes available. The official Node.js release table lists v24 Krypton as LTS as of this May 2026 update, which is why I target it here instead of the newer Current line.
Embeddings are where cost starts hiding
import OpenAI from "openai";
export const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
maxRetries: 3,
timeout: 45_000,
});
export async function embed(input: string) {
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input,
});
return response.data[0].embedding;
}I use the small embedding model first because retrieval quality is usually dominated by chunking and filters, not by buying the largest vector on day one. Upgrade only after you have a retrieval test set that proves the smaller model is the bottleneck.
Chunking: where most bad RAG starts
Bad chunking creates confident nonsense. Too small and the model gets fragments without meaning. Too large and retrieval brings in unrelated paragraphs. My starting point for docs, help-center content, and internal policies:
- 500-900 tokens per chunk;
- 80-120 token overlap;
- split on headings and paragraphs before hard token counts;
- store title, section heading, source URL, and updated date in metadata;
- never mix two documents into one chunk.
export function chunkText(text: string, maxChars = 3200, overlapChars = 500) {
const paragraphs = text.split(/n{2,}/).map((p) => p.trim()).filter(Boolean);
const chunks: string[] = [];
let current = "";
for (const p of paragraphs) {
if ((current + "nn" + p).length > maxChars && current) {
chunks.push(current);
current = current.slice(-overlapChars);
}
current = current ? `${current}nn${p}` : p;
}
if (current) chunks.push(current);
return chunks;
}This is intentionally plain. I reach for smarter parsers only after the corpus demands it: PDFs with tables, code docs, API references, or compliance documents where headings carry legal meaning.
Ingestion breaks when documents are messy
import { pool } from "./db";
import { embed } from "./openai";
import { chunkText } from "./chunk";
export async function ingestDocument(input: {
title: string;
sourceUrl?: string;
text: string;
}) {
const client = await pool.connect();
try {
await client.query("BEGIN");
const doc = await client.query(
"insert into documents(title, source_url) values($1, $2) returning id",
[input.title, input.sourceUrl ?? null],
);
const chunks = chunkText(input.text);
for (let i = 0; i < chunks.length; i++) {
const content = chunks[i];
const embedding = await embed(content);
await client.query(
`insert into document_chunks
(document_id, chunk_index, content, token_count, metadata, embedding)
values ($1, $2, $3, $4, $5, $6)`,
[
doc.rows[0].id,
i,
content,
Math.ceil(content.length / 4),
{ title: input.title, sourceUrl: input.sourceUrl },
`[${embedding.join(",")}]`,
],
);
}
await client.query("COMMIT");
return { documentId: doc.rows[0].id, chunks: chunks.length };
} catch (err) {
await client.query("ROLLBACK");
throw err;
} finally {
client.release();
}
}For large corpora, do not embed inside one long database transaction. Queue the chunks, embed in workers, mark ingestion status per document. The small version above is readable; the production version uses the BullMQ job pattern.
Retrieval is where most bad answers begin
import { pool } from "./db";
import { embed } from "./openai";
export async function retrieve(question: string, limit = 6) {
const queryEmbedding = await embed(question);
const result = await pool.query(
`select
c.id,
c.content,
c.metadata,
d.title,
d.source_url,
1 - (c.embedding <=> $1::vector) as score
from document_chunks c
join documents d on d.id = c.document_id
order by c.embedding <=> $1::vector
limit $2`,
[`[${queryEmbedding.join(",")}]`, limit],
);
return result.rows;
}Log the scores. If your top score is weak and the chunks read unrelated, the correct answer is not “ask the model harder.” The correct answer is to refuse, improve chunking, add filters, or rerank. With pgvector HNSW, remember that filtering can happen after the approximate index scan; if tenant or permission filters are selective, measure recall instead of assuming the index returns enough usable rows.
Answering with citations
The model gets the retrieved chunks, not the whole corpus. I number the chunks and force citations to those numbers.
export async function answerQuestion(question: string) {
const chunks = await retrieve(question, 6);
if (!chunks.length || Number(chunks[0].score) < 0.55) {
return { answer: "I do not have enough source material to answer that.", citations: [] };
}
const context = chunks.map((c, i) => {
return `Source [${i + 1}]
Title: ${c.title}
URL: ${c.source_url ?? "internal"}
Text:
${c.content}`;
}).join("nn---nn");
const response = await openai.responses.create({
model: process.env.OPENAI_MODEL ?? "gpt-5-mini",
instructions: [
"Answer using only the provided sources.",
"If the sources do not support the answer, say so.",
"Cite sources inline as [1], [2], etc.",
"Do not invent citations."
].join(" "),
max_output_tokens: 900,
input: `Question: ${question}nn${context}`,
});
return {
answer: response.output_text,
citations: chunks.map((c, i) => ({ n: i + 1, title: c.title, url: c.source_url })),
};
}This does not magically prevent hallucination, but it makes unsupported answers easier to catch. In production I also run an eval set: 50-100 real questions with expected source IDs. If a chunking change lowers citation accuracy, it does not ship.
Streaming makes bad retrieval fail faster
For a user-facing RAG endpoint, stream. Waiting for retrieval plus full generation makes the app feel broken.
app.post("/ask", async (req, res) => {
const { question } = req.body;
const chunks = await retrieve(question, 6);
res.setHeader("content-type", "text/event-stream");
res.setHeader("cache-control", "no-cache");
res.flushHeaders();
const controller = new AbortController();
req.on("close", () => controller.abort());
const stream = await openai.responses.create({
model: process.env.OPENAI_MODEL ?? "gpt-5-mini",
stream: true,
max_output_tokens: 900,
instructions: "Answer only from the retrieved sources. Cite chunks as [1], [2], etc.",
input: buildRagInput(question, chunks),
}, { signal: controller.signal });
for await (const event of stream) {
if (event.type === "response.output_text.delta") {
res.write(`data: ${JSON.stringify({ delta: event.delta })}nn`);
}
}
res.write("data: [DONE]nn");
res.end();
});The abort hook matters. Without it, a user closing the tab does not stop the model call. You still pay for the answer nobody reads. The broader streaming pattern is in the OpenAI API Node.js guide.
The retrieval tests I run before demo day
RAG quality should not be judged by vibes. Keep a tiny test set:
[
{
"question": "How long do refunds take?",
"expectedSourceTitle": "Refund policy",
"mustInclude": ["5 business days"]
},
{
"question": "Can enterprise customers use SSO?",
"expectedSourceTitle": "Enterprise security",
"mustInclude": ["SAML", "SCIM"]
}
]Run it after chunking changes, model changes, index changes, and document parser changes. The first time it catches a bad PDF parse before a customer does, you will keep it forever.
The checklist I run before trusting a RAG API
- Document ingestion is idempotent; chunk IDs are stable.
- Chunk metadata includes source URL, title, section, and updated date.
- Vector dimension matches the embedding model.
- Retrieval logs top scores, source IDs, latency, and token cost.
- Weak retrieval produces refusal, not improvisation.
- Answers require citations to retrieved chunks.
- Streaming uses AbortController on client disconnect.
- Eval set covers real user questions and expected sources.
- Private documents are filtered before vector search, not after answer generation.
Sources checked for this version
I rechecked the current OpenAI model docs, the pgvector README, the Node.js release schedule, and HNSW implementation notes before this May 14, 2026 update. The concrete choices above are tied to those sources: text-embedding-3-small for a 1536-dimensional starting point, pgvector HNSW with cosine distance for the Postgres baseline, Node.js 24 LTS for the runtime target, and retrieval tests because vector search quality still depends on chunking, filters, and corpus shape.
FAQ
Should I use pgvector or a dedicated vector database?
Use pgvector first when your app already runs Postgres and the corpus is modest. Move to a dedicated vector database when you need larger scale, complex hybrid search, multi-region retrieval, or operational isolation.
What chunk size should I use for RAG?
Start around 500-900 tokens with 80-120 tokens of overlap, then tune against retrieval tests. The best chunk size depends on document shape.
Which OpenAI embedding model should I start with?
Start with a smaller embedding model unless evals prove it is the bottleneck. Chunking, metadata, filters, and reranking usually matter more than model size early.
How do I stop RAG hallucinations?
You reduce them; you do not eliminate them. Use better retrieval, require citations, refuse weak context, lower temperature, and test against real questions.
Do I need LangChain for this?
Not for the baseline. LangChain can help with prototypes and complex pipelines, but the explicit version above is easier to debug when retrieval quality is the problem.
When RAG is the wrong answer
This is the baseline RAG API. The next layers are hybrid search, reranking, document permissions, and prompt caching. If you are still wiring the OpenAI client, start with the OpenAI API Node.js guide. If ingestion should happen in the background, use the BullMQ guide.
I would not build RAG for content that is small, stable, and easier to model as normal database records. Search plus a boring filter is cheaper, faster, and easier to debug. RAG earns its keep when the source material is large, messy, and changes often enough that hard-coded flows become a liability.