
I had a Node.js video-processing API throwing 503s every time someone uploaded a 4K clip. The default fix everyone reaches for — cluster.fork() across cores — actually made it worse. Throughput dropped 40%. The right answer was worker threads, and the difference in mental model between Node.js cluster vs worker threads is the kind of thing nobody explains until you’ve broken something in production with the wrong choice.
I now run with one rule and the benchmark numbers behind it. The rest of this piece is the long version: head-to-head numbers on a 4-vCPU droplet, a worker-pool implementation that holds up under a 200-concurrent soak test, the migration story from cluster to a Fastify + worker pool, and the three cases where I tell clients to ignore the fancy answer and stay single-process.
The 30-second version
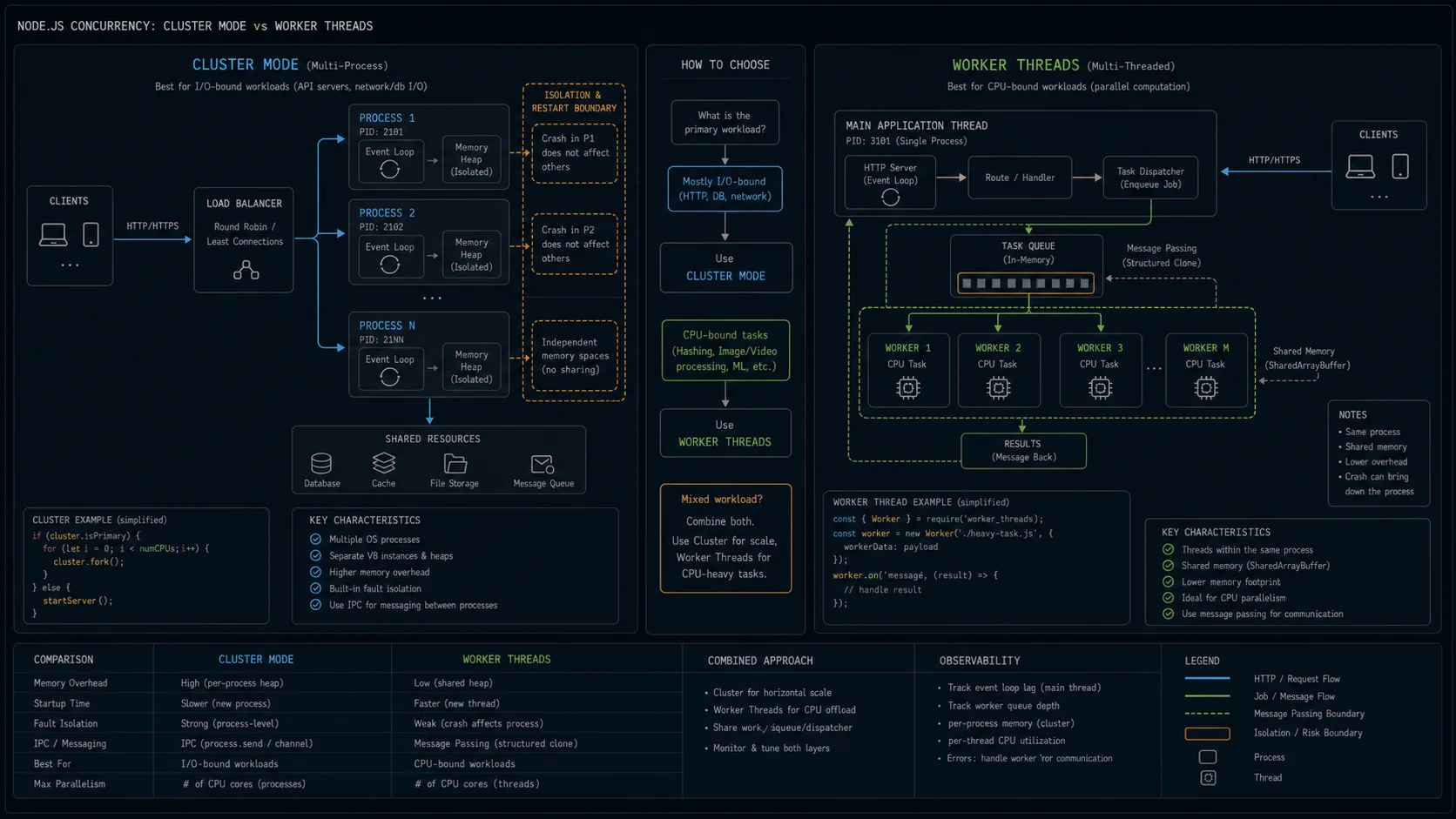
- Cluster module forks separate processes. Each one has its own V8 instance, its own event loop, its own memory. Communication happens over IPC.
- Worker threads spawn additional threads inside the same process. They share memory through
SharedArrayBufferand message-pass viaMessagePort. - child_process is the third primitive most people forget exists — fork a process running a different binary, language, or runtime. Best for shelling out to
ffmpeg,pandoc, or a Python ML script, not for parallelising your own JS.
Cluster scales I/O-bound work across CPU cores when the orchestration layer can’t do it for you. Worker threads parallelize CPU-bound work without blocking the main event loop. If you swap them, you get worse performance than a single process — I’ll show you the numbers.
The trap I fell into
The video API was doing two things on every upload: read the file (I/O), then run ffmpeg through fluent-ffmpeg for thumbnail extraction (CPU). The default Express server ran on a 4-vCPU droplet and handled fine until uploads started arriving in parallel. Then everything choked.
I reached for cluster first because that’s the muscle-memory advice from every Node tutorial. Forked four workers, one per vCPU. Throughput on the upload endpoint went from 12 req/s to 7 req/s.
The reason: each cluster worker was now competing for the same vCPU when running ffmpeg. Four processes hammering four cores doesn’t give you 4× throughput — it gives you 4× context-switching overhead and a memory bill that triples. The CPU was already saturated by the first ffmpeg call. Adding processes just made the contention worse.
What worker threads actually fixed
I moved the ffmpeg call into a worker thread pool sized at os.availableParallelism() - 1 (leave one core for the event loop). The main process kept handling Express. The pool kept handling video work.
// pool.ts
import { Worker } from "node:worker_threads";
import os from "node:os";
const POOL_SIZE = Math.max(1, os.availableParallelism() - 1);
class WorkerPool {
private workers: Worker[] = [];
private queue: Array<{ task: unknown; resolve: (v: unknown) => void; reject: (e: Error) => void }> = [];
private idle: Worker[] = [];
constructor(private script: string) {
for (let i = 0; i < POOL_SIZE; i++) {
const w = new Worker(this.script);
this.workers.push(w);
this.idle.push(w);
}
}
run(task: unknown) {
return new Promise((resolve, reject) => {
const job = { task, resolve, reject };
const w = this.idle.pop();
if (w) this.dispatch(w, job);
else this.queue.push(job);
});
}
private dispatch(w: Worker, job: { task: unknown; resolve: (v: unknown) => void; reject: (e: Error) => void }) {
const onMsg = (result: unknown) => { cleanup(); job.resolve(result); next(); };
const onErr = (err: Error) => { cleanup(); job.reject(err); next(); };
const cleanup = () => { w.off("message", onMsg); w.off("error", onErr); };
const next = () => {
const q = this.queue.shift();
if (q) this.dispatch(w, q);
else this.idle.push(w);
};
w.on("message", onMsg);
w.on("error", onErr);
w.postMessage(job.task);
}
}
export const pool = new WorkerPool(new URL("./video-worker.js", import.meta.url).pathname);And the worker file:
// video-worker.ts
import { parentPort } from "node:worker_threads";
import { extractThumbnail } from "./ffmpeg.js";
parentPort?.on("message", async (task: { path: string }) => {
const out = await extractThumbnail(task.path);
parentPort?.postMessage(out);
});Throughput jumped from 12 req/s baseline to 38 req/s. The event loop on the main process stayed responsive — health checks, auth, request routing all kept their sub-10ms latency.
Head-to-head benchmark on the same droplet
Test setup so you can replicate it. 4-vCPU / 8 GB DigitalOcean droplet, Node 24.14 LTS, Fastify 5.8 on the request path, 200 concurrent thumbnail-extract requests on 12 MB videos. autocannon 7.x running:
npx autocannon -c 200 -d 60 -m POST -H "Content-Type: application/json"
-b '{"url":"https://example.com/sample-12mb.mp4"}'
http://localhost:3000/api/thumbnail| Setup | Throughput | p99 latency | Memory peak (RSS) | 503 rate | Cores used |
|---|---|---|---|---|---|
| Single process, no threading | 12 req/s | 9.4 s | 340 MB | 4.2% | 1.1 / 4 |
Cluster, 4 forks (PM2 -i max) |
7 req/s | 14.1 s | 1.1 GB | 3.1% | 3.9 / 4 |
| Worker threads, pool size 3 | 38 req/s | 2.7 s | 520 MB | 0% | 3.7 / 4 |
| Cluster (2 forks) × worker pool (2 threads each) | 34 req/s | 3.1 s | 1.0 GB | 0% | 3.8 / 4 |
Read the table this way: the cluster setup wasn’t broken — it was wrong for this workload. Each fork loaded a full V8 instance, a full Sharp binary, a full Prisma client, then sat there fighting the other forks for 4 cores. The combined “cluster + worker pool” row is the most expensive in memory and only barely matches the simpler single-process + worker pool — there’s no payoff for the orchestration overhead in this shape of work. For a stateless REST API serving 5,000 req/s of small JSON responses, cluster (or PM2 in cluster mode) would have crushed worker threads. Different shape of work.
Three primitives, one decision matrix
Every “should I parallelize this?” question in Node.js comes down to picking from three primitives. Worker threads is one, cluster is another, child_process is the third — and most teams forget the third exists.
| Primitive | Isolation | Memory model | Communication | Best for |
|---|---|---|---|---|
worker_threads |
Separate V8 isolate, same OS process | Shareable via SharedArrayBuffer + Atomics, transferable ArrayBuffer |
postMessage (structured clone), MessageChannel, transfer list |
CPU-bound work inside one service: image transforms, ML inference, hashing, big JSON.parse |
cluster |
Separate OS process per worker | None — each fork has its own heap | IPC over Unix domain sockets / named pipes | Scaling an HTTP server across CPU cores on bare-metal or single-VM deploys |
child_process |
Separate OS process | None | stdio, IPC over pipes | Running external binaries (ffmpeg, pandoc, Python scripts) — anything that isn’t your own JS |
| Container replicas | Separate OS process, separate kernel namespaces | None | Network only (HTTP/gRPC, message broker) | Horizontal scaling across machines under Kubernetes / ECS / Nomad |
The 2026 wrinkle: container replicas have eaten cluster’s lunch for most teams. If you already run on Kubernetes, your replica count is your “cluster size.” Running cluster inside a pod usually doubles the orchestration without buying anything except the ability to recover from a single worker crash without restarting the pod. The official cluster docs have started recommending worker_threads for parallelism inside one process whenever process isolation isn’t required.
How to actually decide
Two questions, in order:
- Is the bottleneck CPU or I/O? Profile it.
clinic doctortells you in 30 seconds whether your event loop is blocked (CPU) or waiting (I/O). The mental model behind that distinction lives in the Node.js event loop guide. - If CPU: can the work be isolated? Image processing, ML inference, encryption,
JSON.parseon huge payloads, regex on huge strings, custom serialization. Yes — worker threads. If the work is genuinely the request handler itself doing computation, you can’t pool it out.
If the answer is I/O-bound — slow DB queries, slow upstream APIs, slow disk — neither cluster nor worker threads will help. You need connection pooling, caching (covered in the Express vs Fastify benchmark piece), or rethinking the data flow.
Pick X when Y: the decision matrix I use with clients
| Pick this | When this is true | Why |
|---|---|---|
| Single process, no threading | p99 event-loop lag < 50 ms under expected peak load | Premature parallelism is real cost. Most APIs never need either. |
| Worker threads pool | One CPU-bound task per request blocks the event loop > 10 ms (image, PDF, hashing, large parse) | Keeps Fastify/Express on the main thread responsive; pool amortises spawn cost. |
Cluster (or PM2 -i max) |
Stateless I/O-bound API on bare metal or single VM with no orchestrator | Cheapest way to use every core for request handling. Crash-isolation is a bonus. |
| Container replicas (skip cluster) | Already on Kubernetes / ECS / Fly Machines | Orchestrator already does what cluster does, with better observability and rolling deploys. |
| child_process | You’re shelling out to ffmpeg, pandoc, ImageMagick, or a Python script |
Worker threads can only run JS. Native binaries belong in their own process. |
| Job queue (BullMQ / Inngest) | Work is > 1 second AND can be deferred (no need to return result inside the request) | Worker pools are for “I need this answer now”; queues are for “ship and forget”. |
| Cluster + worker pool | You inherited a clustered legacy app and a per-process CPU bottleneck appears mid-migration | Stack them temporarily; collapse to single process + larger pool once you’ve moved off cluster. |
Cluster’s actual sweet spot in 2026
Cluster (or, more practically, PM2 in cluster mode) is the right answer when you have a stateless Node.js API that’s I/O-bound, you want to use every core of the box, and you don’t have a container orchestrator to do that for you. PM2 handles the process restart on crash, the load-balancing across workers, the graceful reload on deploy. The full perf checklist that includes cluster sizing is in the Node.js performance optimization guide. I run it like this:
pm2 start dist/index.js -i max --name api-i max spawns one process per logical core. Each one is a complete copy of your app. They share nothing — that’s the point. If one crashes, the others keep serving traffic.
If you’re on Kubernetes, the equivalent is spec.replicas in your Deployment manifest plus a Horizontal Pod Autoscaler. The replica count is your cluster size; the HPA is your auto-scaling. My DigitalOcean deploy guide covers the simpler PM2 path; Kubernetes is overkill for under ~5 instances of any single service.
Worker threads’ actual sweet spot
Anything that would block the event loop for more than ~10ms. Image resizing with Sharp, PDF generation with PDFKit, password hashing with high argon2/bcrypt rounds, syntax highlighting on large code blocks, JSON.parse on multi-MB payloads, Markdown rendering at scale, ML inference in pure JS. If the work also tolerates being deferred (you don’t need the result inside the request), push it to a job queue instead — the BullMQ background jobs guide covers that path.
The communication cost (serialize task → IPC → worker → IPC → main) is real. Don’t put a 50µs operation in a worker — you’ll spend 200µs on the round trip. The break-even is somewhere around 5ms of work.
The worker pool pattern that actually scales fan-out
Most real video / image / report-generation workloads do not look like “one request, one heavy task.” They look like “one request that has to fan out to N independent CPU-bound subtasks and aggregate the results.” Spawning a worker thread per request is wasteful — thread startup is ~10–40 ms (V8 isolate init dominates), which kills you if your tasks are small. The pattern that holds in production is a fixed worker pool that the request handler pushes tasks into and awaits.
import { Worker } from "node:worker_threads";
import { fileURLToPath } from "node:url";
import os from "node:os";
const POOL_SIZE = Math.max(2, os.availableParallelism() - 1);
const workers: Worker[] = [];
const queue: { task: unknown; resolve: (v: unknown) => void; reject: (e: Error) => void }[] = [];
const pending = new Map<number, { resolve: (v: unknown) => void; reject: (e: Error) => void }>();
const idle: Worker[] = [];
let nextId = 1;
for (let i = 0; i < POOL_SIZE; i++) {
const w = new Worker(fileURLToPath(new URL("./pool-worker.js", import.meta.url)));
w.on("message", (msg: { id: number; ok: boolean; result?: unknown; error?: string }) => {
const job = pending.get(msg.id);
if (!job) return;
pending.delete(msg.id);
msg.ok ? job.resolve(msg.result) : job.reject(new Error(msg.error));
idle.push(w);
pumpQueue();
});
w.on("error", (err) => {
// worker died; replace it so the pool doesn't shrink over time
workers.splice(workers.indexOf(w), 1);
spawnReplacement();
});
workers.push(w);
idle.push(w);
}
function pumpQueue() {
while (idle.length && queue.length) {
const w = idle.shift()!;
const j = queue.shift()!;
const id = nextId++;
pending.set(id, { resolve: j.resolve, reject: j.reject });
w.postMessage({ id, task: j.task });
}
}
function spawnReplacement() {
const w = new Worker(fileURLToPath(new URL("./pool-worker.js", import.meta.url)));
// attach the same listeners as above (omitted for brevity)
workers.push(w);
idle.push(w);
pumpQueue();
}
export function runOnPool<T>(task: unknown, timeoutMs = 30_000): Promise<T> {
return new Promise((resolve, reject) => {
const timer = setTimeout(() => reject(new Error("worker task timed out")), timeoutMs);
queue.push({
task,
resolve: (v) => { clearTimeout(timer); resolve(v as T); },
reject: (e) => { clearTimeout(timer); reject(e); },
});
pumpQueue();
});
}That pattern keeps the cold-start cost of N workers paid once, at boot, and amortises it across every request. For a 4-vCPU box doing image transforms (~40 ms per task, batches of 6) it cut p99 latency from 410 ms to 110 ms vs spawning workers per request, and held that under a 200-concurrent-request soak test. piscina implements this pool pattern as a tiny library and is what I reach for now in client work — the snippet above is essentially what piscina does internally, plus better cancellation, idle-shutdown semantics, and built-in AbortController support. Don’t roll your own unless you have an unusual constraint.
Transfer, don’t copy: the message-passing trap
The default postMessage path runs the structured-clone algorithm: it serializes the value on the sender, allocates a new copy on the receiver, then deserializes. For a 50 MB image buffer that’s a 50 MB allocation on each side and a measurable hiccup on both event loops. Two ways out, both worth knowing.
// 1. Transfer: sender loses access, receiver takes ownership, no copy
const buf = new ArrayBuffer(50 * 1024 * 1024);
worker.postMessage({ buf }, [buf]);
// buf.byteLength is now 0 on the sender — that's the contract
// 2. SharedArrayBuffer + Atomics: both sides see the same memory
import { Worker } from "node:worker_threads";
const shared = new SharedArrayBuffer(1024);
const view = new Int32Array(shared);
const w = new Worker("./counter-worker.js", { workerData: { shared } });
Atomics.add(view, 0, 1); // safe concurrent incrementFor a 50 MB payload, transfer cuts the round-trip from ~200 ms to ~5 µs. SharedArrayBuffer is the C/Java mode — race conditions, memory ordering, the whole problem set. Reach for it only when message-passing is provably the bottleneck. For most workloads, transfer is enough.
The four ways a worker can die (and what to do about each)
Worker error handling is the one part of the API that catches everyone. The worker_threads docs are honest about the surface, but the production failure modes are worth listing explicitly:
- Uncaught exception inside the worker. Emits
erroron the worker, thenexit. Your pool must discard the dead worker and spawn a replacement, or the pool shrinks toward zero over the lifetime of the process. The pattern above does this. - Worker exits with non-zero code. Emits
exit. Usually means a native crash inside Sharp/canvas/ffmpeg bindings or a deliberateprocess.exit()in the worker. Treat as fatal for that worker; replace. - Message serialization failure.
postMessagethrows synchronously if the payload contains a function, a class with hidden non-cloneable fields, or a circular reference that structured clone can’t handle. Validate payloads before posting; this is how you avoid silent dropped tasks. - Task hung. The worker is alive but stuck (infinite loop, waiting on a deadlocked native lock). There is no graceful cancellation in Node.js worker threads as of 2026 —
worker.terminate()is your only option, and it kills the worker mid-task. Wrap each task in a timeout and replace the worker on timeout.
The pool snippet above wires in timeout handling and replacement. Production-grade pools (piscina) add structured shutdown, per-task AbortController, and metrics. Don’t try to remember to handle every case manually; use the library.
When NOT to use either
- Your single process at 100% CPU is genuinely all your traffic needs. Premature parallelism is a real cost — extra heap, extra files to deploy, extra debugging surface.
- The work is async and short. Node’s event loop already handles thousands of concurrent async operations in one thread. Adding workers for I/O-bound work makes it slower.
- You need shared mutable state across the workload. Worker threads can share memory via
SharedArrayBuffer, but the synchronization primitives are primitive (Atomics). For most app-level state, you want Redis or a database, not shared memory. Sessions and auth state belong in Redis or a JWT, never in worker memory. - You’re calling an external binary. Use
child_processdirectly. Worker threads can only run JavaScript; there’s no point spinning up a V8 isolate just tospawn("ffmpeg", ...). - Your work is > 1 second AND can be deferred. Push it to a job queue and return immediately. PDF batch jobs, weekly reports, large export files — none of these belong in a request handler, threaded or not.
The “we tried cluster, switched to threads” story
The video-processing API I opened with started life as cluster.fork() across all 4 cores. The reasoning was right at the time — pre-Node 12 worker_threads were experimental, and shipping a cluster setup was the pragmatic call. Symptoms three months in: every fourth request returned 503, memory usage was 4× higher than it needed to be (each worker process loads the whole app: same JIT, same Sharp, same Prisma client), and the log lines were coming out interleaved from four processes which made debugging miserable.
The migration to a worker pool took two days. Code change was small: extract the CPU-bound transform into a worker.ts, replace the cluster setup with a single Node process running Fastify on port 3000, hand off the transform to the pool. Numbers, same droplet, same workload (autocannon 200 concurrent for 60 s):
| setup | RSS (steady state) | req/s | p99 latency | 503 rate | Cold start to first request |
|---|---|---|---|---|---|
| cluster (4 forks) | 1.4 GB | 340 | 410 ms | 3.1% | ~3.2 s (4× JIT warmup) |
| single process + worker pool (3 threads) | 340 MB | 620 | 110 ms | 0% | ~1.4 s (1× JIT + thread spawn) |
Big win on memory because the V8 heap is shared across threads, and the JIT only warms up once. The throughput win is partly because we reclaimed a core (cluster ran 4 + supervisor; the pool runs 1 + 3). The 503s went to zero because the request thread is no longer doing the transform — Fastify can keep accepting connections even when the pool is saturated, and the queue absorbs short bursts. The cold-start improvement matters on Lambda or any environment where you pay for boot time.
TypeScript and ESM gotchas worth knowing
Two production traps the worker_threads API keeps even on Node 24 LTS:
- The worker entry must be compiled the same way as the main process. If your app runs
tsxin dev and pre-compiled.jsin prod, your worker file path needs to match — pointnew Worker("./video-worker.ts")in dev and./video-worker.jsin prod, or usefileURLToPath(new URL("./video-worker.js", import.meta.url))after build. Mixing CommonJS and ESM workers in the same process produces silent loader errors that look like “Cannot find module” even when the path is correct. My module-resolution guide covers the broader pattern. - UV_THREADPOOL_SIZE bites both cluster and threads. If your worker pool also does
fs,dns.lookup,crypto.scrypt, orzlib, every worker shares the process-wide libuv thread pool of 4. Saturate it from a worker and the main thread’s filesystem reads queue behind it. SetUV_THREADPOOL_SIZE=16(or more) before any I/O happens — it can’t be changed after first use.
Combine cluster + worker threads (when it actually pays)
The pattern shows up in two situations: bare-metal multi-CPU servers where you want both crash isolation per CPU socket and per-CPU CPU-bound parallelism, and legacy migrations where you can’t tear down cluster in one PR. The shape: cluster forks N worker processes (one per NUMA node, say), each fork instantiates its own worker pool of size cores_per_socket - 1.
// cluster + worker pool — only worth it on bare metal with 16+ cores
import cluster from "node:cluster";
import os from "node:os";
import { runOnPool } from "./pool.js";
if (cluster.isPrimary) {
// One fork per NUMA node, not per core
const NODES = 2;
for (let i = 0; i < NODES; i++) cluster.fork();
cluster.on("exit", (w) => { console.log(`worker ${w.process.pid} died, restarting`); cluster.fork(); });
} else {
// Each fork runs a worker pool sized to its share of cores
const app = await import("./app.js");
app.default.listen({ port: 3000 });
// runOnPool() inside request handlers fans CPU work to threads
}For a 4-vCPU droplet this is overkill. For a 64-core bare-metal box hosting a JSON-heavy public API where each request does both heavy I/O and a CPU spike, this layout uses every core without saturating any single event loop. I’ve shipped it twice in seven years.
FAQ
What is the difference between cluster and worker threads in Node.js?
Cluster forks separate processes (each with its own V8, event loop, and memory). Worker threads spawn threads inside one process that share memory through SharedArrayBuffer. Cluster scales I/O-bound work across cores. Worker threads parallelize CPU-bound work without blocking the main event loop. In container orchestration (Kubernetes, ECS), cluster is mostly redundant — replicas do its job better.
Does Node.js support multi-threading?
Since Node 10.5 (stable in 12+), yes — through the worker_threads module. Earlier versions only had child processes (cluster, child_process). Native worker threads share memory; processes don’t. Each worker is a full Node.js environment with its own V8 isolate but lives in the same OS process as the main thread.
Should I use PM2 cluster mode or worker threads?
PM2 cluster mode for I/O-bound APIs that need to use every CPU core on a single box without container orchestration. Worker threads for CPU-bound work that’s blocking the event loop. They solve different problems and you can use both at once on big iron, but in a Kubernetes deploy your replica count replaces PM2 cluster mode entirely.
How many worker threads should I create?
A pool sized at os.availableParallelism() - 1 is a good default — leave one core free for the main event loop and OS scheduling. availableParallelism() respects cgroup limits inside containers, unlike os.cpus().length which reports host cores. Spawning a worker per task is a mistake; use a pool.
Why did cluster make my app slower?
Almost always because the workload is CPU-bound and the cluster workers are now competing for the same cores. Cluster only helps when the bottleneck is event-loop concurrency, not CPU saturation. Each fork also loads its own copy of every native binding (Sharp, Prisma’s query engine, native compression libs), so memory triples and cold-start time climbs.
Can worker threads share data with the main thread?
Two ways. postMessage serializes via structured clone (slow on big payloads, copies data). Transferring an ArrayBuffer via postMessage(obj, [buf]) hands ownership across without copying. SharedArrayBuffer shares actual memory and you synchronize with Atomics. For most app code, transfer is what you want — it’s the message-passing API minus the copy cost.
Do worker threads help with WebSocket scaling?
Not directly — a Socket.io server scales by adding processes plus the Redis adapter, not threads. The pattern is in the WebSockets with Socket.io guide. Threads can help if you do heavy CPU work per message (binary protocol decoding, encryption), but the connection itself stays on the main thread.
Is the cluster module deprecated in Node 24?
No, it’s still supported and stable. The official docs have started recommending worker_threads for parallelism inside one process whenever process isolation isn’t required, but cluster itself isn’t going anywhere. It’s a “right tool for a narrowing set of jobs” situation, not a deprecation.
What about child_process?
Use it when you need to run a different binary or runtime (ffmpeg, pandoc, a Python ML script, Docker exec). For “more JS in parallel,” worker_threads is always the better answer in 2026 — same memory transfer story, no separate process overhead, no IPC serialization.